부하 테스트란?
· 임계값 한게에 도달할 때까지 시스템의 부하를 지속적으로 꾸준히 증가시켜 시스템을 테스트하는 것
· 성능 테스트의 하위 집합
부하 테스트의 목적
· 버퍼 오버플로, 메모리 누수 및 잘못된 메모리 관리와 관련된 응용 프로그램의 결함을 노출한다.
· 부하 테스팅의 결과로 발견되는 문제는 로드 밸런싱 문제, 대역폭 문제, 기존 시스템의 용량 등이 포함될 수 있다.
· 데이터베이스, 하드웨어, 네트워크 등의 응용 프로그램의 모든 구성 요소의 상한을 결정한다.
· 미래에 예상되는 애플리케이션에 대한 부하를 관리할 수 있도록 한다.
성능 테스트란?
· 특정 부하에서 응답성 및 안정성 측면에서, 시스템이 어떻게 동작하는지 측정하기 위한 비기능 테스트
· 확장성, 신뢰성 및 리소스 사용과 같은 시스템의 다른 품질 속성을 조사, 측정, 검증할 수 있다.
· 목적: 시스템의 병목 지점을 찾는 것
성능 테스트 종류
· 부하 테스트, 스트레스 테스트, 내구성 테스트 (Endurance/Soak Testing), 최고점 부하 테스트 (Spike Testing)
부하 테스트 도구
부하를 발생 시키는 도구
· Jmeter
· nGrind
· Gatling
모니터링 도구 - APM
· Application Performance Management의 약자로, 응용 소프트웨어의 성능과 서비스 가용성을 모니터링하고 관리하는 도구
· 종류:
- 제니퍼
- Elastic APM
- 와탭
- PinPoint
▶ Java로 작성된 대규모 분산 시스템용 APM 도구
▶ Transaction 추적을 제공
▶ 임계치를 설정하여, Event 발생시 SMS 또는 Email을 통해 알림을 받을 수 있다.
▶ 우아한형제들, 네이버, NHN 등에서 사용중
부하 테스트 진행 순서
1. 주요 시나리오 테스트
- 주요 시나리오 선정 후 시나리오별로 얼마나 견디는지 테스트
2. 트랜잭션별 단위 테스트
- 각 트랜잭션별로 얼마나 견디는지 테스트
3.주요 시나리오 가중치 테스트
- 각 시나리오의 가중치를 부여하여 얼마나 견디는지 테스트 ex) A 시나리오 30%, B 시나리오 70%
4. 테스트 결과 공유
5. 개선 후 다시 테스트
6. 결과 분석
부하 테스트 진행
목적
1. 실제 서비스 운영시 서버가 버틸 수 있는 최대 사용자 수 구하기
2. 질문 - 로드 밸런서를 이용한 서버 두 대의 성능은 서버 하나의 X2 배 만큼 성능을 낼까?
3. 현재 서버의 문제점 찾기
진행하면서 느꼈던 점
· 너무 작은 부하는 요청이 전부 빠른 시간 내에 성공하므로 의미가 없고,
너무 큰 부하는 거의 모든 요청이 실패하므로 의미가 없다. 적절한 부하를 선택하여 지속적으로 부하를 늘려가자.
선택한 도구
· jmeter, pinpoint
부하 툴은 jmeter를 선택했다. 무료로 사용할 수 있으며, 계획한 시나리오 테스트를 진행하는데 기능상 문제가 없었고, 마침 백기선님의 'The Java Test' 강의라는 좋은 학습 자료를 이미 구입했기 때문이다.
모니터링 툴은 pinpoint를 선택했다. pinpoint는 무료로 사용할 수 있으며, 인프라로 구성한 분산 서버를 테스트하기 위한 전용 기능들을 제공하고, 이미 네이버, NHN, 우아한형제들과 같은 대용량 트래픽을 다루는 업체들에서도 사용할 정도로 검증이 된 도구이다.
또한 현재 클라우드로 사용 중인 네이버 클라우드 플랫폼에서는 pinpoint를 쉽게 설정하고 사용할 수 있는 pinpoint cloud까지 지원해주었기 때문에 해당 도구를 선택했다.
테스트할 서버 구조
테스트할 서버의 구조는 아래와 같다. Jmeter를 통해 들어오는 요청을 로드 밸런서가 받아서 두 개의 스프링 서버(1번, 2번 서버로 칭함)로 전달하다. 두 개의 스프링 서버는 하나의 MySQL 데이터베이스를 공유하고 있다.

테스트 절차
▶ jmeter 설치
https://scshim.tistory.com/444
▶ pinpoint 설치
https://scshim.tistory.com/445
▶ 시나리오 준비
A. 급상승 아파트 목록 조회 (금액 기준) -> 급상승 아파트 목록 조회 (상승% 기준) [기존 회원]
B. 회원가입 -> 로그인 -> 아파트 목록 조회 [신규 회원]
▶ 시나리오 테스트
- A 시나리오를 50개의 스레드로 1분간 로드밸런서에 지속적으로 요청
총 4,172개의 요청을 처리했고, 대 부분 1초 미만으로 처리할 정도로 양호한 응답 속도를 보여주었다.
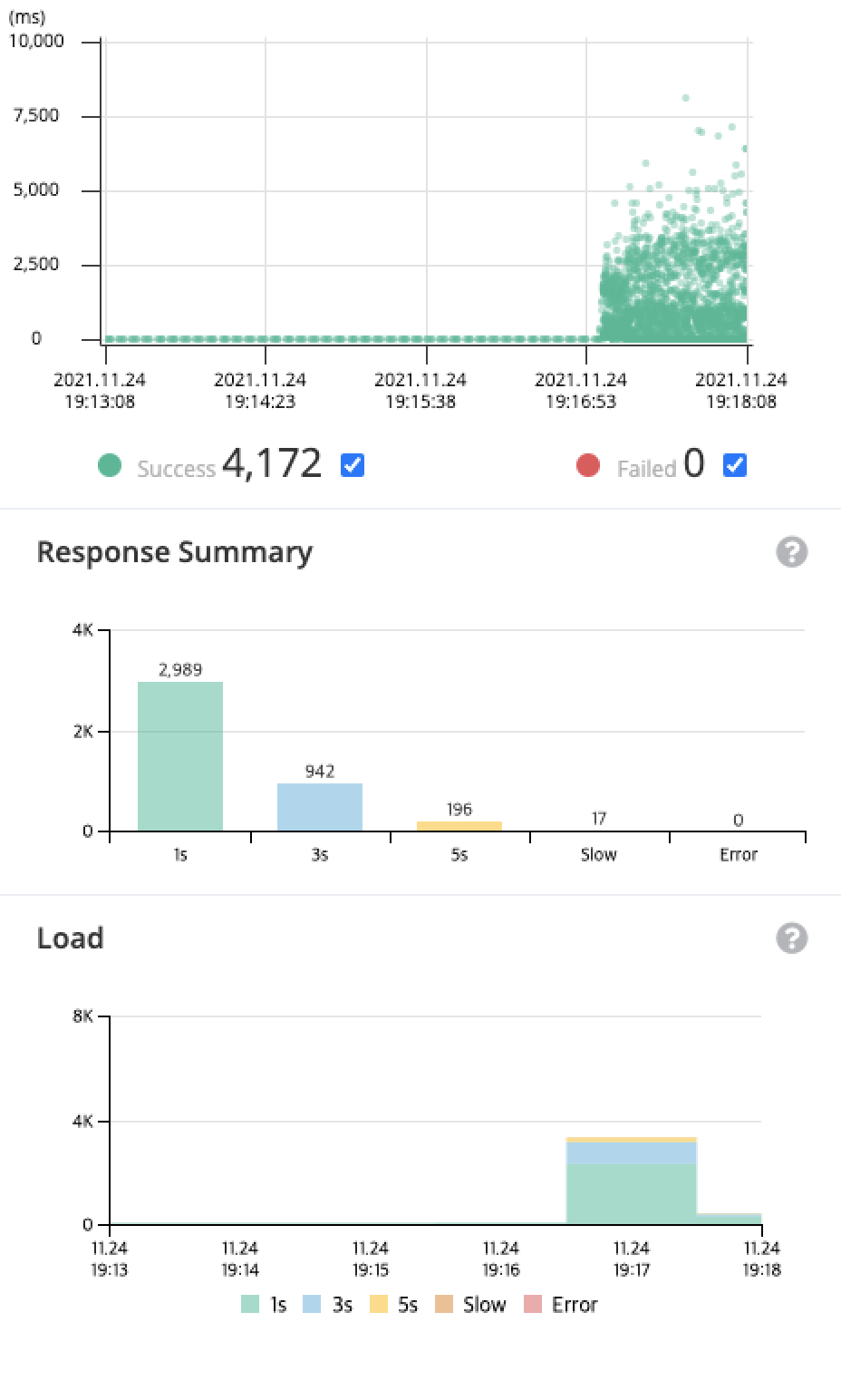
대부분의 요청이 고른 응답 시간을 보였지만, 직사각형 위에 물방울이 조금 튄 것 처럼 혼자서 응답시간이 긴 응답들이 존재했다.

pinpoint는 그래프에서 세부사항을 보기를 원하는 부분을 드래그하면, 해당 요청들을 자세히 볼 수 있다.

해당 요청들은 모두 login 요청들이었다. 서버 부하를 줄이기 위해서는 다른 요청 보다 우선순위로 login 요청을 수정해야겠다는 생각을 했다.
이번에는 1번과 2번 서버 각각의 지표를 살펴보자. 1번 서버와 2번 서버 모두 비슷한 요청 처리량을 보여주었다.
하지만 Response Summary를 확인하면, 1번 서버가 2번 서버보다 훨씬 응답 시간이 긴 것을 알 수 있다.
여기서 1번 서버가 무언가 문제가 있을 수도 있다는 생각이 들었다.
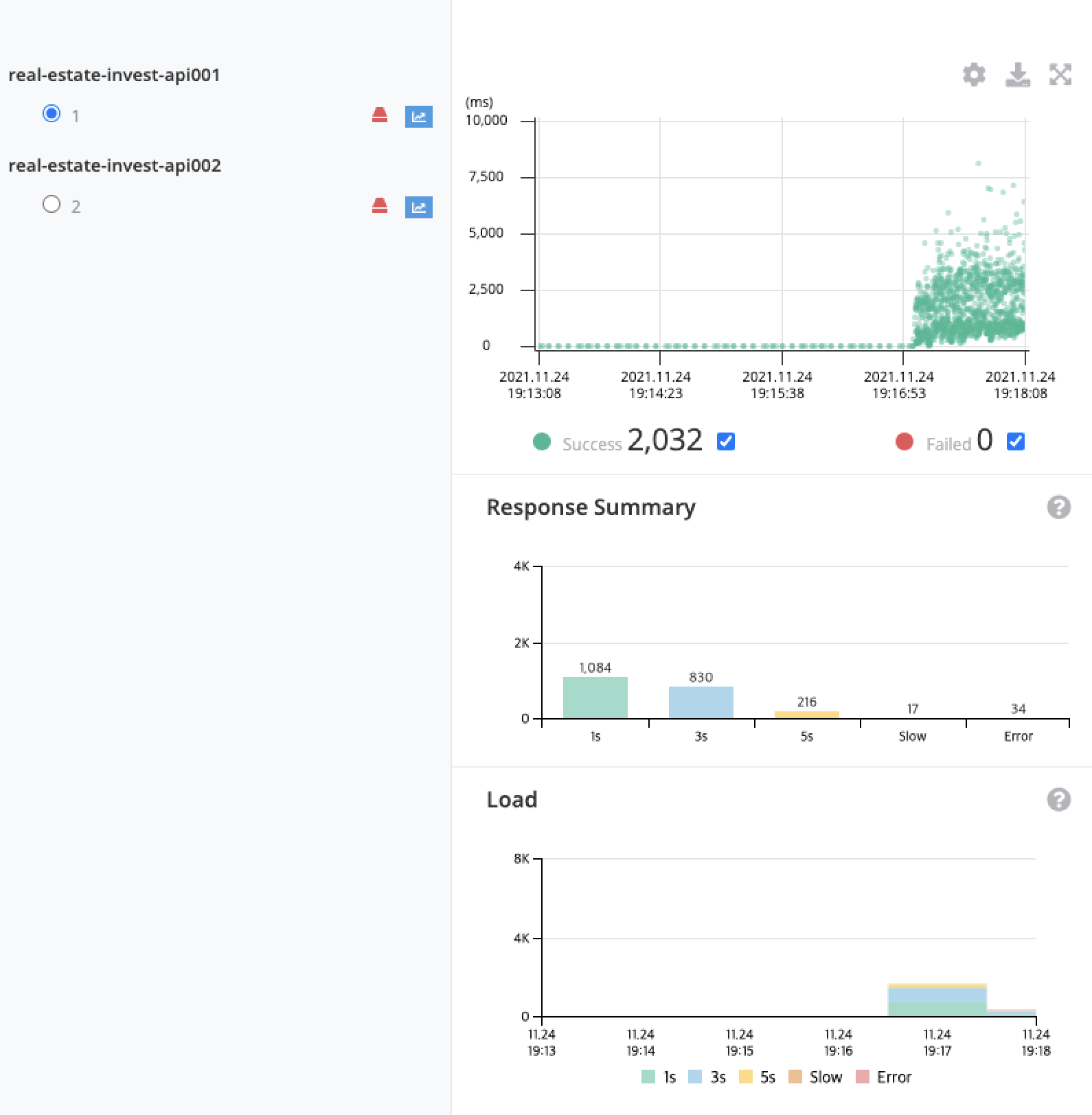

- A 시나리오를 50개의 스레드로 1분간 지속적으로 1번 서버와 2번 서버에 각각 요청
앞서 부하 테스트의 목적으로 '로드 밸런서를 이용한 서버 두 대의 성능은 서버 하나의 X2 배 만큼 성능을 낼까?'라는 질문을 했다.
실험 전 생각은 로드밸런서에서 '라운드로빈 알고리즘'을 통해 부하를 각 서버에 분산하기 때문에 해당 알고리즘 연산에 따른 시간이 걸려서 로드 밸런서를 이용하는 것 보다 1번 서버와 2번 서버에 요청을 각각 보내는 것이 처리량이 더 많을 것이라 생각했다.
이 질문을 해결하기 위해 방금 전 실행한 테스트와 같은 요청을 로드 밸런서가 아닌 1번 서버와 2번 서버에 각각 보냈다.
아래는 1번 서버의 결과다.

아래는 2번 서버의 결과다.

결과 적으로 '로드 밸런서를 이용한 서버 두 대의 성능은 서버 하나의 X2 배 만큼 성능을 낼까?'라는 질문의 답은 YES 였다.
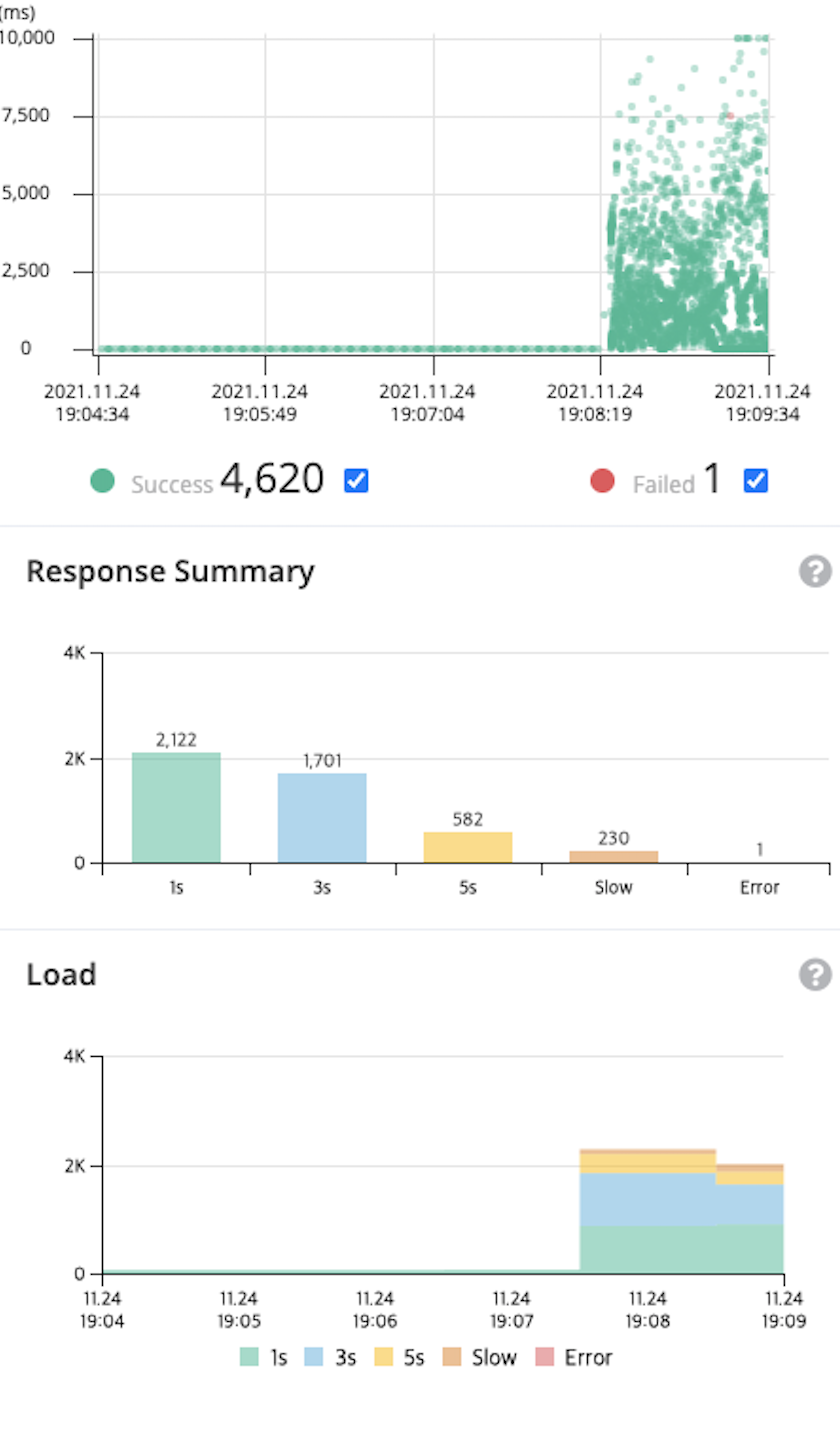
- A 시나리오를 100개의 스레드로 1분간 로드밸런서에 지속적으로 요청
50개의 스레드로 요청을 했을 때보다 처리량이 급격히 늘지 않았다. (약 10% 증가)
하지만 응답 속도는 확연히 느려졌다. 응답 속도가 1초 이내인 요청과 3초 이내인 요청이 비슷해졌다.
매우 작은 수지만, 오류가 발생하기 시작했다.
해당 데이터로 현재 안정적으로 요청을 처리할 수 있는 동시 사용자 수는 50~100명으로 판단되었다.
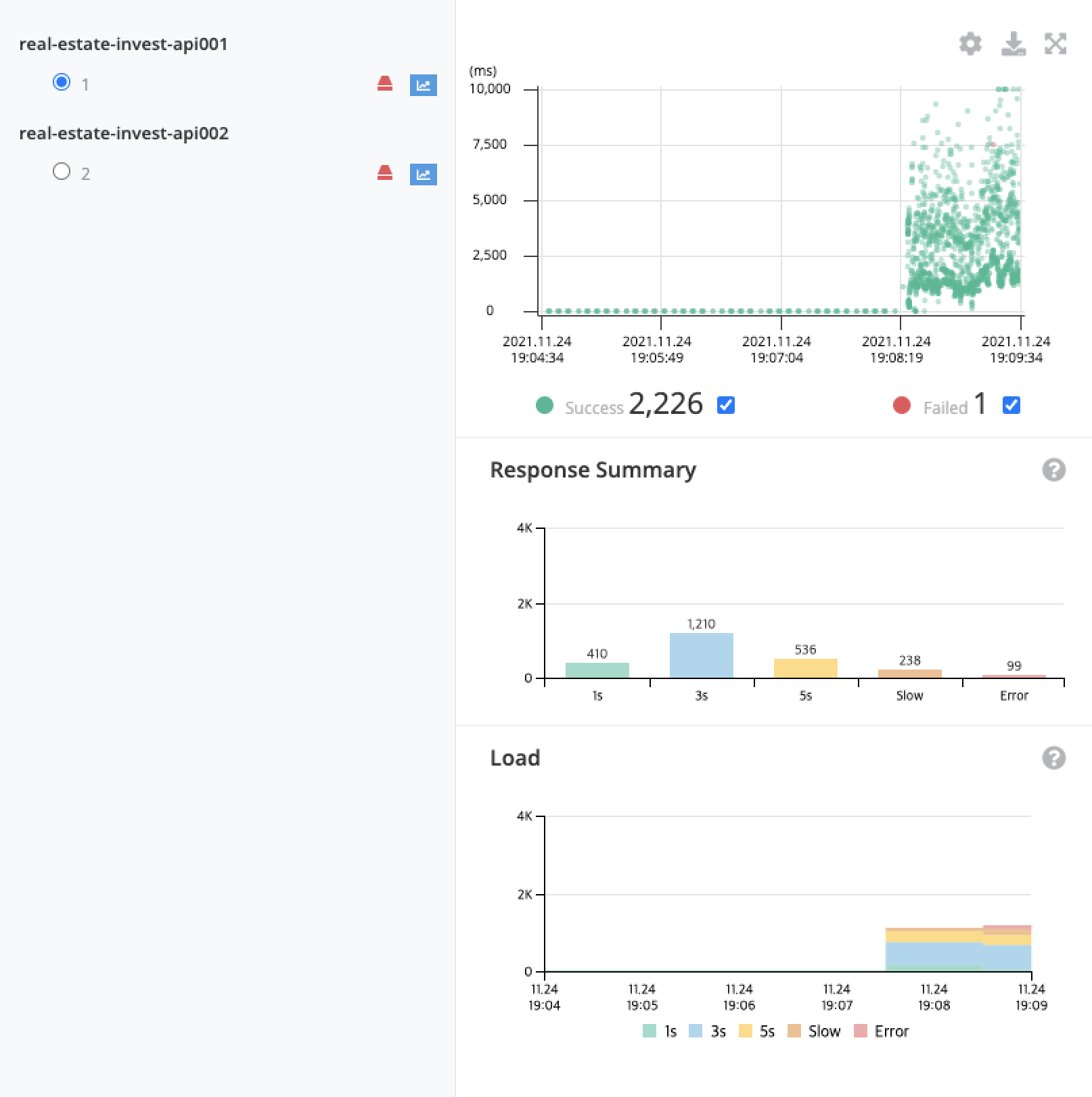
1번 서버와 2번 서버의 지표를 각각 살펴보자.
두 서버의 처리량은 비슷했다.
하지만 응답 속도에서 훨씬 차이가 나기 시작했다.
2번 서버가 대부분 1초 이내의 응답 속도를 보여준 반면, 1번 서버의 응답 속도는 그것보다 훨씬 느렸다.
1번 서버에서는 무언가 문제가 발생하고 있을 것이다.

- A 시나리오를 200개의 스레드로 1분간 로드밸런서에 지속적으로 요청
스레드의 개수는 늘렸지만, 오히려 처리량이 줄어들기 시작했다.
응답 속도 또한 처참햇다. 5초 이상의 느린 응답속도와 1초 미만의 빠른 응답속도를 가진 요청의 수가 비슷해졌다.
오류 또한 상당히 들어났다.

1번 서버와 2번 서버의 지표를 각각 살펴보자.
1번 서버는 스레드가 100개인 상황에서 테스트했을 때와 비슷한 지표를 보였다.
하지만 이전 테스트에서 건강한 모습을 보여준 2번 서버에서 slow한 응답 속도의 요청이 훨씬 늘어났다.
이는 요청 초반에만 집중된 현상이므로 JVM Warm Up을 통해 해결해 봐야겠다 (https://www.baeldung.com/java-jvm-warmup)
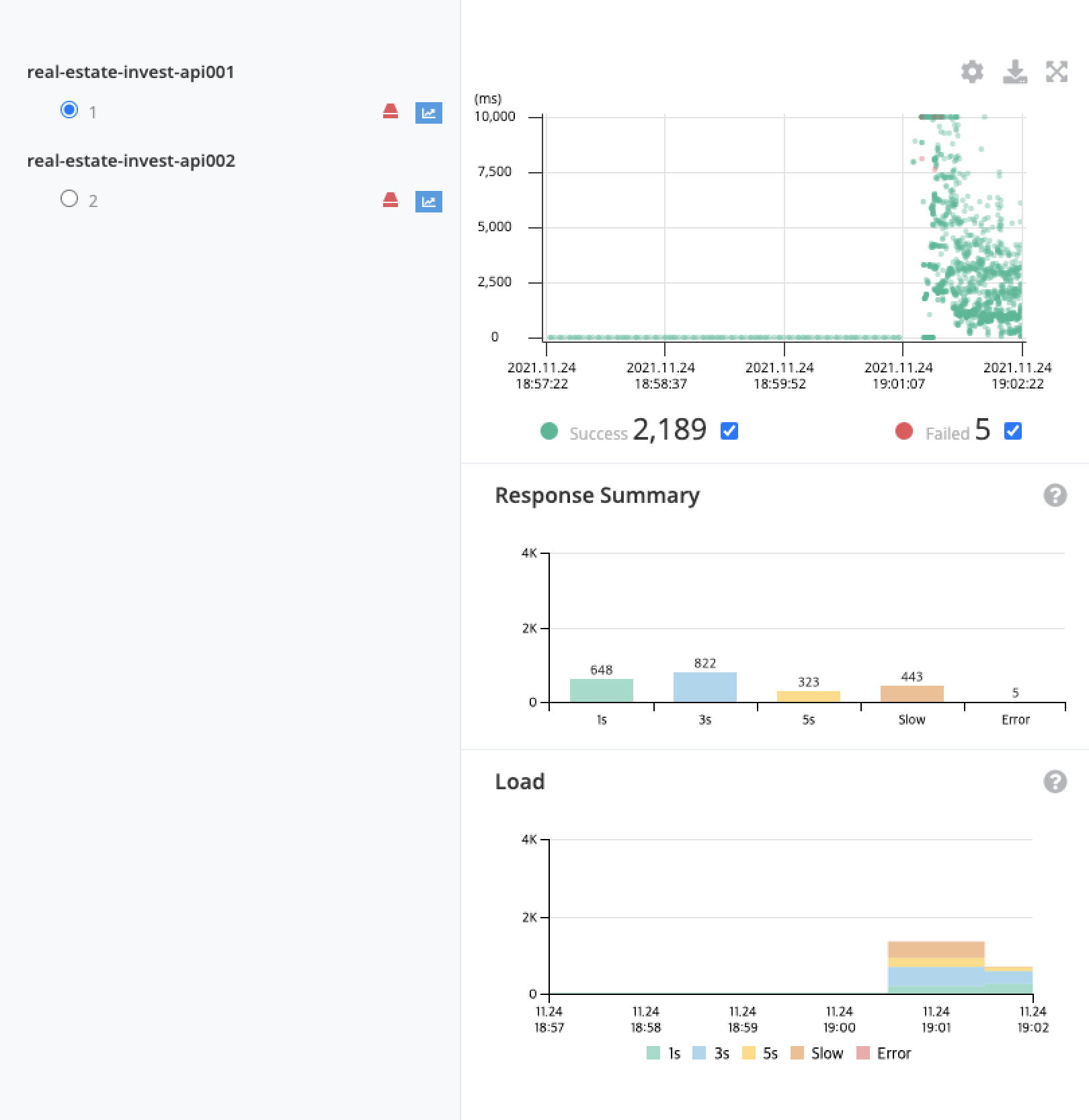

서버 2번이 어디까지 버티는지 살펴보기 위해 더 큰 부하는 주었다.
- A 시나리오를 300개의 스레드로 1분간 로드밸런서에 지속적으로 요청
이번에는 2번 서버가 버티지 못했다. 오류 또한 증가하고, 응답 속도도 느려졌다.
2번 서버가 버릴 수 있는 한계는 200~300개 사이의 스레드로 추정되었다.

테스트를 진행하면서 구성한 서버의 개선할 점들을 확인했다. 생각보다 많은 시간이 소요되어 테스트는 이후에 이어가야겠다.
시나리오 B도 테스트를 진행하고, 문제점을 개선한 후에도 다시 테스트를 진행해봐야겠다.
출처
- https://aws.amazon.com/ko/blogs/korea/how-to-loading-test-based-on-aws/
- https://www.slideshare.net/arload/bestcon-load-test
- https://techblog.woowahan.com/2572/
https://www.softwaretestinghelp.com/what-is-performance-testing-load-testing-stress-testing/
http://developer.gaeasoft.co.kr/development-guide/knowledge/apm/pinpoint/pinpoint-practice/
'백엔드' 카테고리의 다른 글
| [Cookie] 쿠키를 주고 받을 때 HTTP 요청과 응답에 어떤 헤더 데이터가 오가는가? 쿠키 값을 어떻게 인코딩하나? (0) | 2021.10.14 |
|---|---|
| 웹 프로그래밍 기초 - URL과 웹 페이지, 웹 브라우저와 웹 서버, HTML과 HTTP, 정적 자원과 동적 자원 (0) | 2021.10.02 |
| [Nginx] 멀티 도메인 지원하기 (0) | 2021.04.06 |
| [Nginx] 유저 ip를 통해 Nginx에 들어오는 요청 차단/허용하기 (0) | 2021.04.03 |



댓글