학습할 것
· 문자열 인코딩이란?
· 아스키 코드란?
· EUC-KR이란?
· 유니코드란?
· UTF-8이란?
· UTF-16이란?
· UTF-32이란?
문자열 인코딩이란?
᛫ 2진법을 사용하는 컴퓨터가 인간의 언어를 일정한 규칙에 따라 2진수로 변환하는 방식
᛫ 이때, 2진수와 문자는 문자 집합을 통해 일대일로 대응
ex) 아스키 코드, EUC-KR, UTF-8, UTF-16, UTF-32
ex) 안녕하세요 -> %EC%95%88%EB%85%95%ED%95%98%EC%84%B8%EC%9A%94%0A (UTF-8)
᛫ 문자 집합: 컴퓨터에서 문자를 어떠한 코드로 저장할 것인가 정의해둔 것
ex)유니코드, ISO-8859,ASCII
아스키 코드란?
᛫ 처음으로 표준을 정립한 문자열 인코딩 방식
᛫ 대문자, 소문자, 아라비아 숫자, 공백 및 특수 문자
᛫ 0~127까지 128개의 숫자를 사용하여 문자 표현

예시 - 아스키코드로 문자를 표현 (자바)
public class CharacterEncoding {
public static void main(String[] args) throws UnsupportedEncodingException {
CharacterEncoding characterEncoding = new CharacterEncoding();
String text = "Hello";
String encodingType = "ascii";
characterEncoding.printText(text,encodingType);
}
public void printText(String text, String encodingType) throws UnsupportedEncodingException {
byte [] byteDate = text.getBytes(encodingType);
StringBuilder hexStringBuilder = new StringBuilder();
StringBuilder decStringBuilder = new StringBuilder();
for (byte c : byteDate) {
int decimal = c & 0xff;
decStringBuilder.append(decimal).append(" ");
hexStringBuilder.append(Integer.toString(decimal+ 0x100, 16).substring(1)).append(" ");
}
System.out.println("문자열 '" + text+ "'의 길이:"+text.length());
System.out.println("문자를 표현하는 데 사용한 바이트 수:"+text.getBytes(encodingType).length);
System.out.println("16진수 값:"+hexStringBuilder);
System.out.println("10진수 값:"+decStringBuilder);
}
}
문자열의 길이 5글자를 표현하기 위해 5바이트 메모리를 사용하며, 10진수 값을 위에 ASCII CODE TABLE과 비교하면 'Hello' 문자가 되는 걸 확인할 수 있다.
EUC-KR이란?
- 우리나라에서 컴퓨터로 한글을 표현하기 위해 문자 집합을 만든 것
- 한국 산업 표준으로 지정된 한국어 문자 집합으로 문자 하나를 2바이트로 표현
-아스키 코드 문자를 표현할 때는 1바이트를 사용하므로 아스키 코드와 호환

유니코드란?
᛫ 국제 표준화 기구(ISO)에서 만든 동일한 규칙으로 모든 언어를 표현할 수 있는 문자 집합
᛫ 1991년 개발, 이후 여러 언어를 지속적으로 추가 (2020-03-10 기준 13.0에 거란 문자 등 추가)
᛫ 유니코드 문자 집합을 표현하는 다양한 문자열 인코딩이 존재 (UTF-8, UTF-16, UTF-32)
개발목적
᛫ 국가별로 독자적인 문자열 인코딩을 사용하는 문제를 해결하기 위해
과거에는 EUC-KR처럼 국가별로 독자적인 문자 집합과 인코딩 방식을 사용했다. 따라서 전 세계 사용자를 대상으로 하는 프로그램이나 웹 페이지를 만들려면 다른 인코딩 방식을 사용했다. 이는 작업에 많은 시간이 드는 일이었다.
UTF-8이란?
᛫ 인코딩 단위를 8비트(1바이트)로 하여 유니코드 문자 집합을 표현하는 포맷
᛫ 표현하려는 문자에 따라 최소 1바이트에서 최대 6바이트까지 사용 (가변 길이 문자 인코딩)
᛫ 아스키 코드와 호환
᛫ 윈도우, 자바, 임베디드를 제외한 거의 모든 환경의 문자열 처리 표준 ex) JSON은 UTF-8 인코딩만 사용
UTF-8 표현 규칙

᛫ Number of bytes: 문자를 표현하는 데 사용하는 총 바이트
᛫ Byte1 ~ Byte6까지 있는 1과 0은 고정된 비트 값, 사용하는 바이트 수에 따라 달라짐. 'x'문자는 유니코드 저장에 사용할 비트 영역
᛫ Number of byte: 1
- 첫 번째 비트 값 0을 제외한 나머지 비트 7개로 문자 표현
- 0부터 127까지의 수로 문자를 표현하는 아스키 코드와 같은 규칙을 사용하여 아스키 코드와 완벽히 호환됨
᛫ Number of byte: 2
- 첫 번째 바이트에서 110을 제외한 비트 5개, 두 번째 바이트에서 10을 제외한 비트 6개를 조합하여 총 11개의 비트로 UTF-8을 만들수 있음
᛫ 일반적인 문자는 3바이트 내로 처리되며, 이모지는 4바이트, 고대문자 등을 5바이트로 표현
예시 - UTF-8 문자열 출력
public class CharacterEncoding {
public static void main(String[] args) throws UnsupportedEncodingException {
CharacterEncoding characterEncoding = new CharacterEncoding();
String english = "Hello";
String hangul = "안녕하세요";
String encodingType = "utf-8";
characterEncoding.printText(english,encodingType);
characterEncoding.printText(hangul,encodingType);
}
public void printText(String text, String encodingType) throws UnsupportedEncodingException {
byte [] byteDate = text.getBytes(encodingType);
StringBuilder hexStringBuilder = new StringBuilder();
StringBuilder decStringBuilder = new StringBuilder();
for (byte c : byteDate) {
int decimal = c & 0xff;
decStringBuilder.append(decimal).append(" ");
hexStringBuilder.append(Integer.toString(decimal+ 0x100, 16).substring(1)).append(" ");
}
System.out.println("문자열 '" + text+ "'의 길이:"+text.length());
System.out.println("문자를 표현하는 데 사용한 바이트 수:"+text.getBytes(encodingType).length);
System.out.println("16진수 값:"+hexStringBuilder);
System.out.println("10진수 값:"+decStringBuilder);
}
}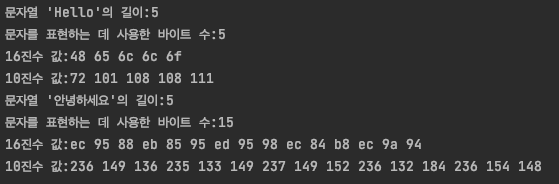
UTF-8 조합 규칙 예시 - 한글 문자열 인식
위 결과를 보면 한글 5글자를 표현하는 데 15 바이트를 사용한다. 즉, 글자당 3바이트를 사용한다.
문자 '안'을 구성하는 16 진수 값은 ec, 95, 88이다. 이를 2진수로 표현하면 각각 1110 1100 / 1001 0101 / 1000 1000이다.
해당 형태는 위에 UTF-표현 규칙 Number of Bytes 3에 해당한다.

여기서 고정 비트는 1110 / 10 / 10을 각각 제외하면 1100010101001000이 만들어진다. 이것을 16진수로 변환하면 0xC548이된다. 0xC548은 유니코드에서 정의한 규칙에 따라 문자 '안'을 의미한다.

나머지 문자 '녕하세요'도 같은 방법으로 계산한다.
추가내용 - MySQL
᛫ MySQL의 UTF-8 타입에는 utf8과 utf8mb4가 존재
᛫ utf8은 3바이트까지 정상적으로 처리하나 4바이트 영역 문자는 처리 불가
- 때문에 utf8은 이모지 등의 4바이트 영역 문자 처리 불가
᛫ UTF-8과 완벽히 호환되는 문자 집합을 쓰고 싶다면 utf8mb4를 사용해야함
UTF-16이란?
᛫ 인코딩 단위를 16비트(2바이트)로 하여 유니코드 문자 집합을 표현하는 포맷
᛫ 2바이트 또는 4바이트만 사용하므로 아스키코드와 호환 x
᛫ 자바와 윈도우의 문자열 처리 표준
- 자바와 윈도우는 유니코드를 사용하기 전부터 고정된 2바이트 길이의 문자 집합을 사용하여 호환성을 위해 UTF-8을 표준으로 사용
᛫ 유니코드에는문자 종류에 따라 기본 다국어 평면(BMP), 보충 다국어 평면(SMP), 상형 문자 보충 평면(SIP), 특수 목적 보충 평면(SSP) 등의 평면이 존재하고, 바이트 수는 표현하려는 문자의 소속에 따라 결정
ex) BMP는 U+0000~U+FFFF 범위에 속하며 한글, 한자 등이 이 범위에 포함되고 2바이트로 인코딩된다. 이러한 일반적인 문자 외에 BMP 범위를 벗어나는 특벽한 문자들은 4바이트로 인코딩된다.
예시 - UTF-16 문자열 출력
public class CharacterEncoding {
public static void main(String[] args) throws UnsupportedEncodingException {
CharacterEncoding characterEncoding = new CharacterEncoding();
String english = "Hello";
String hangul = "안녕하세요";
String encodingType = "utf-8";
characterEncoding.printText(english,encodingType);
characterEncoding.printText(hangul,encodingType);
}
public void printText(String text, String encodingType) throws UnsupportedEncodingException {
byte [] byteDate = text.getBytes(encodingType);
StringBuilder hexStringBuilder = new StringBuilder();
StringBuilder decStringBuilder = new StringBuilder();
for (byte c : byteDate) {
int decimal = c & 0xff;
decStringBuilder.append(decimal).append(" ");
hexStringBuilder.append(Integer.toString(decimal+ 0x100, 16).substring(1)).append(" ");
}
System.out.println("문자열 '" + text+ "'의 길이:"+text.length());
System.out.println("문자를 표현하는 데 사용한 바이트 수:"+text.getBytes(encodingType).length);
System.out.println("16진수 값:"+hexStringBuilder);
System.out.println("10진수 값:"+decStringBuilder);
}
}
᛫ 일반 글자를 표현할 때 2바이트를 사용하고, 아스키 코드와 호환되지 않으므로 10바이트가 사용된다.
᛫ 여기에 바이트 순서 표시 2바이트(16진수 출력 결과의 fe ff)가 추가되어 'Hello', '안녕하세요' 문자열 모두 12바이트로 표현 가능하다.
᛫ UTF-16은 특수한 경우(쇄기문자)를 제외하고 2바이트로 끊어 읽음
- 위의 코드를 실행한 컴퓨터는 빅 엔디언 컴퓨터다. 따라서 순서를 그대로 읽는다.
- 0048: H / 0065: E / 006c: L / 006c: L / 006f: O
- 한글도 이와 같은 방식으로 표현
바이트 순서 표시(Byte Order Mark)
᛫ UTF-16, UTF-32에서 사용
᛫ 문자열 맨 앞에 2바이트에 0xFEFF(유니코드 U+FEFF)를 표기하여 사용한다는 의미
᛫ OxFE, OxFF 중 어떤 문자가 먼저 오는지에 따라 리틀 엔디언, 빅 엔디언으로 나뉜다
- 따라서 두 방식에 따라 문자열 인코딩 시 바이트 데이터를 조합하는 순서가 바뀐다
᛫ BOM으로 바이트 표현 순서를 정의하는 이유: CPU 설계에 따라 바이트 값의 처리 순서가 다르므로
- CPU가 OxFEFF를 읽을 때 리틀 엔디언 방식은 OxFF 다음 OxFF를 읽고, 빅 엔디언 방식은 반대로 읽는다
- 0x12345678 표현이 있을 때 리틀 엔디언은 78 56 34 12, 빅 엔디언은 12 34 56 78로 읽는다.
4바이트로 표현하는 문자인 경우
᛫ 리틀 엔디언 기준으로 두 번째 바이트가 110110으로 시작하면, 2 바이트 대신 4바이트로 읽어 처리
᛫ 앞 2바이트에 110110을 제외한 모든 값과 뒤에 오는 2바이트의 110111을 제외한 모든 값을 합쳐 유니코드 생성
110110yy yyxxxxxx 110111xx xxxxxxxx
UTF-32이란?
᛫ 인코딩 단위를 32비트(4바이트)로 하여 유니코드 문자 집합을 표현하는 포맷
᛫ 4바이트를 고정적으로 사용
출처
᛫ 학교에서 알려주지 않는 17가지 실무 개발 기술
'컴퓨터공학' 카테고리의 다른 글
| [Computer Science] SGML이란? , <!-- --> 주석의 유래 (0) | 2021.10.14 |
|---|---|
| MVVM vs MVC, 장점과 단점 (0) | 2021.10.14 |
| 카오스 엔지니어링과 카오스 몽키 (0) | 2021.10.14 |
| [Computer Science] 스핀락(spinlock)의 정의와 사용 이유 (0) | 2021.09.13 |
| [Computer Science] 교착상태(deadlock), 발생 조건과 방지 방법 (0) | 2021.09.12 |



댓글