목차
· 아이템 42. 익명 클래스보다는 람다를 사용하라
· 아이템 43. 람다보다는 메서드 참조를 사용하라
· 아이템 44. 표준 함수형 인터페이스를 사용하라
· 아이템 45. 스트림은 주의해서 사용하라
· 아이템 46. 스트림에서는 부작용 없는 함수를 사용하라
· 아이템 47. 반환 타입으로는 스트림보다 컬렉션이 낫다
· 아이템 48. 스트림 병렬화는 주의해서 적용하라
· 자바 8에서 함수형 인터페이스, 람다, 메서드 참조 개념이 추가되면서 함수 객체를 더 쉽게 만들 수 있게 되었다.
· 이와 함께 스트림 API가 추가되어 데이터 원소의 시퀸스 처리를 라이러리 차원에서 지원하기 시작했다.
· 위 기능들을 효과적으로 사용하는 방법을 알아보자.
아이템 42. 익명 클래스보다는 람다를 사용하라
핵심 정리
· 자바 8부터 작은 객체를 구현하는 데 적합한 람다가 도입되었다.
· 익명 클래스는 함수형 인터페이스가 아닌 타입의 인스턴스를 만들 때만 사용하자.
· 람다는 작은 함수 객체를 아주 쉽게 표현할 수 있어 (이전 자바에서는 실용적이지 않던) 함수형 프로그래밍의 지평을 열었다.
자바 8 이전의 함수
· 예전에는 자바에서 함수 타입을 표현할 때 추상 메서드를 하나만 담은 인터페이스(드물게는 추상 클래스)를 사용했다.
- 이런 인터페이스의 인스턴스를 함수 객체라고 하여, 특정 함수나 동작을 나타내는 데 썼다.
· JDK 1.1 부터 함수 객체를 만드는 주요 수단은 익명 클래스(아이템 24)가 되었다.
다음 코드는 문자열을 길이순으로 정렬하기 위한 비교 함수로 익명 클래스를 사용한다.
// 익명 클래스의 인스턴스를 함수 객체로 사용 - 낡은 기법
Collections.sort(words, new Comparator<String>(){
public int compare(String s1, String s2) {
return Integer.compare(s1.length(), s2.length());
}
});
전략 패턴[Gamma95]처럼 함수 객체를 사용하는 과거 객체 지향 디자인 패턴에는 익명 클래스면 충분했다.
- 위 코드에서 Comparator 인터페이스가 정렬을 담당하는 추상 전략을 뜻하고, 구체적인 전략을 익명 클래스로 구현했다.
익명 클래스의 단점: 너무 길기 때문에 자바는 함수형 프로그래밍에 적합하지 않았다.
자바 8 이후의 함수
· 자바 8부터 추상 메서드 하나짜리 인터페이스가 특별한 의미를 인정받아 함수형 인터페이스로 불리게 되었고, 이 인터페이스들의 인스턴스를 람다식(또는 람다)을 사용해 만들 수 있게 되었다.
· 람다는 함수나 익명 클래스와 개념은 비슷하지만, 코드는 훨씬 간결하다.
- 또한 자질구레한 코드가 사라져 어떤 동작을 하는지 더 명확하다.
다음은 익명 클래스를 사용한 앞의 코드를 람다 방식으로 바꾼 모습이다.
// 람다식을 함수 객체로 사용 - 익명 클래스 대체
Collections.sort(words, (s1, s2) -> Integer.compare(s1.length(), s2.length()));
· 위 코드에서 람다, 매개변수, 반환값의 타입의 언급은 없다. 컴파일러가 문맥을 살펴 타입을 추론해준 것이다.
- 실제 타입은 각각 (Comprator<String>),String, int다.
- 상황에 따라 컴파일러가 타입을 결정하지 못할 수도 있는데, 그럴 때는 프로그래머가 직접 명시해야 한다.
· 아이템 26의 '제네릭의 로 타입을 쓰지 말라', 아이템 29의 '제네릭을 쓰라', 아이템 30의 '제네릭 메서드를 쓰라'고 했던 조언 들은 람다와 함께 쓸때는 두 배로 중요하다. 컴파일러가 타입을 추론하는 데 필요한 타입 정보 대부분을 제네릭에서 얻기 때문이다.
- 우리가 이 정보를 제공하지 않으면 컴파일러는 람다의 타입을 추록할 수 없게 되어, 우리가 일일이 명시해야한다(코드가 너저분해짐).
· 타입을 명시해야 코드가 더 명확할 때만 제외하고, 람다의 모든 매개변수 타입은 생략하자.
- 컴파일러가 "타입을 알 수 없다"는 오류를 낼 때만 해당 타입을 명시한다.
람다 자리에 비교 생성 메서드를 사용하면 위 코드를 더 간결하게 만들 수 있다(아이템 14, 43).
Collections.sort(words, comparingInt(String::length));
자바 8의 List 인터페이스에 추가된 sort 메서드를 이용하면 더욱 짧아진다.
words.sort( comparingInt(String::length));
람다의 장점 - 함수 객체의 실용적 사용
· 람다를 언어 차원에서 지원하면서 기존에는 적합하지 않았던 곳에서도 함수를 실용적으로 사용할 수 있게 되었다.
다음은 아이템 34의 Operation 열거 타입이다. apply 메서드의 동작이 상수마다 달라야 해서 상수별 클래스의 몸체를 사용해 각 상수에서 apply 메서드를 재정의해야했다.
public enum Operation {
PLUS("+") {
public double apply(double x, double y) { return x + y; }
},
MINUS("-") {
public double apply(double x, double y) { return x - y; }
},
TIMES("*") {
public double apply(double x, double y) { return x * y; }
},
DIVIDE("/") {
public double apply(double x, double y) { return x / y; }
};
private final String symbol;
Operation(String symbol) { this.symbol = symbol; }
@Override public String toString() { return symbol; }
public abstract double apply(double x, double y);
}
· 람다를 이용하면 열거 타입의 인스턴스 이용하여, 상수별로 다르게 동작하는 코드를 쉽게 구현할 수 있다.
각 열거 타입 상수의 동작을 람다로 구현해 생성자에 넘기고, 생성자는 이 람다를 인스턴스 필드로 저쟁해둔다. 그런 다음 apply 메서드에서 필드에 저장된 람다를 호출한다.
- 이렇게 구현하면 원래 버전보다 간결하고 깔끔해진다.
public enum Operation {
PLUS ("+", (x, y) -> x + y),
MINUS ("-", (x, y) -> x - y),
TIMES ("*", (x, y) -> x * y),
DIVIDE("/", (x, y) -> x / y);
private final String symbol;
private final DoubleBinaryOperator op;
Operation(String symbol, DoubleBinaryOperator op) {
this.symbol = symbol;
this.op = op;
}
@Override public String toString() { return symbol; }
public double apply(double x, double y) {
return op.applyAsDouble(x, y);
}
}
람다 vs 상수별 클래스 몸체
· 람다는 이름이 없고, 문서화도 못 한다. 따라서 코드 자체로 동작이 명확히 설명되지 않거나 코드 줄 수가 많아지면 쓰지 말아야 한다.
· 람다는 길어지면 가독성이 심하게 나빠진다.
- 한 줄일 때 가장 좋고, 길어도 세 줄 안에 끝내는 게 좋다.
- 람다가 길거나 읽기 어렵다면 람다를 쓰지 말아야 한다.
· 열거 타입 생성자에 넘겨지는 인수들의 타입은 컴파일타임에 추론된다. 따라서 열거 타입 생성자 안의 람다는 열거 타입의 인스턴스 멤버에 접근할 수 없다 (인스턴스는 런타임에 만들어지기 때문이다).
· 상수별 동작을 단 몇 줄로 구현하기 어렵거나, 인스턴스 필드나 메서드를 사용해야만 하는 상황이면, 상수별 클래스 몸체를 사용하자.
람다 vs 익명클래스
· 람다는 함수형 인터페이스에서만 쓰이므로, 추상 클래스의 인스턴스를 만들 때 람다를 쓸 수 없으니 익명 클래스를 써야 한다.
· 추상 메서드가 여러 개인 인터페이스의 인스턴스를 만들 때 익명 클래스를 쓸 수 있다.
· 함수 객체가 자신을 참조해야 한다면 익명 클래스를 써야 한다.
- 람다는 자신을 참조할 수 없다. 람다에서 this 키워드는 바깥 인스턴스를 가리킨다.
- 반면, 익명클래스에서의 this는 익명 클래스의 인스턴스 자신을 가리킨다.
· 람다도 익명 클래스처럼 직렬화 형태가 구현별로(예: 가상머신별로) 다를 수 있다. 따라서 람다를 직렬화하는 일은 삼가야 한다(익명 클래스 인스턴스로 마찬가지).
- 직렬화해야만 하는 함수 객체가 있다면(Comparator 등) private 정적 중첩 클래스(아이템 24)의 인스턴스를 사용하자.
아이템 43. 람다보다는 메서드 참조를 사용하라
핵심 정리
· 메서드 참조는 람다의 간단명료한 대안이 될 수 있다. 메서드 참조 쪽이 짧고 명확하다면 메서드 참조를 쓰고, 그렇지 않을 때만 람다를 사용하라.
메서드 참조
· 메서드 참조(method reference)는 함수 객체를 람다보다도 더 간결하게 만드는 방법이다.
메서드 참조 사용 예시
다음 코드는 임의의 키와 Integer 값의 매핑을 관리하는 프로그램의 일부다. 키가 맵 안에 없다면 키와 숫자 1을 매핑하고, 이미 있다면 기존 매핑 값을 증가시킨다.
map.merge(key, 1, (count, incr) -> count + incr);
이 코드는 자바 8 때 Mpap에 추가된 merge 메서드를 사용했다. merge 메서드는 키, 값, 함수를 인수로 받으며, 주어진 키가 맵 안에 아직 없다면 주어진 [키, 값] 쌍을 그대로 저장한다. 반대로 키가 이미 있다면, 세 번째 인수로 받은 함수를 현재 값과 주어진 값에 적용한 다음, 그 결과로 현재 값을 덮어쓴다.
· 람다 대신 메서드 참조를 전달하면 똑같은 결과를 더 보기 좋게 얻을 수 있다.
- 매개변수 count와 incr는 크게 하는 일 없이 공간을 꽤 차지한다.
- 자바 8이 되면서 기본 타입의 박싱 타입은 이 람다와 기능이 같은 정적 메서드 sum을 제공하기 시작했다.
map.merge(key, 1, Integer::sum);
메서드 참조와 람다의 차이점
· 매개변수 수가 늘어날수록 메서드 참조로 제거할 수 있는 코드양도 늘어난다. 하지만 어떤 람다에서는 매개변수의 이름 자체가 프로그래머에게 좋은 가이드가 되기도 한다. 이런 람다는 길이는 더 길지만 메서드 참조보다 읽기 쉽고 유지보수도 쉬울 수 있다.
· 람다로 할 수 없는 일이라면 메서드 참조로도 할 수 없다.
- 단, 유일한 예외가 존재한다. 제네릭 함수 타입 구현이다. 제네릭 함수 타입은 메서드 참조 표현식으로는 구현할 수 있지만, 람다식으로는 불가능하다.
다음과 같은 인터페이스 계층 구조를 생각해보자.
interface G1 {
<E extends Exception> Object m() throws E;
}
interface G2 {
<F extends Exception> String m() throws Exception;
}
interface G extends G1, G2 {
}
이때 함수형 인터페이스 G를 함수 타입으로 표현하면 다음과 같다.
F extends Exception> () -> String throws F
· 메서드 참조에는 기능을 잘 드러내는 이름을 지어줄 수 있고, 친절한 설명을 문서로 남길 수도 있다.
· 람다가 메서드 참조보다 간결할 때가 있다. 주로 메서드와 람다가 같은 클래스에 있을 때 그렇다.
ex) 다음 코드가 GoshThisClassNameIsHumongous 클래스 안에 있다고 해보자.
service.execute(GoshThisClassNameIsHumongous::action);
이를 람다로 대체하면 다음처럼 된다. 이 경우 메서드 참조 쪽은 더 짧지도, 더 명확하지도 않다. 따라서 람다 쪽이 낫다.
service.execute(() -> action());
같은 선상에서 java.util.function 패키지가 제공하는 제네릭 정적 팩터리 메서드인 Function.identity()를 사용하기보다는 똑같은 기능의 (x -> x)를 사용하는 편이 코드도 짧고 명확하다.
메서드 참조의 유형
· 메서드 참조의 유형은 다섯 가지가 있다.
1. 정적 메서드를 가리키는 메서드 참조
인스턴스 메서드를 참조하는 유형 두 가지
2. 수신 객체(receiving object, 참조 대상 인스턴스)를 특정하는 한정적(bound) 인스턴스 메서드 참조
- 한정적 참조는 근본적으로 정적 참조와 비슷하다. 즉, 함수 객체가 받는 인수와 참조되는 메서드가 받는 인수가 똑같다.
3. 수신 객체를 특정하지 않는 비한정적(unbound) 인스턴스 메서드 참조
- 비한정적 참조에서는 함수 객체를 적용하는 시점에 수신 객체를 알려준다. 이를 위해 수신 객체 전달용 매개변수가 매개변수 목록의 첫 번째로 추가되며, 그 뒤로는 참조되는 메서드 선언에 정의된 매개변수들이 뒤따른다.
- 비한정적 참조는 주로 스트림 파이프라인에서의 매핑과 필터 함수에 쓰인다(아이템 45).
4. 클래스 생성자를 가리키는 메서드 참조
5. 배열 생성자를 가리키는 메서드 참조
- 생성자 참조는 팩터리 객체로 사용된다.
| 메서드 참조 유형 | 예 | 같은 기능을 하는 람다 |
| 정적 | Integer::parseInt | str -> Integer.parseInt(str) |
| 한정적(인스턴스) | Instant.now::isAfter | Instant then = Instant.now(); t -> then.isAfter(t) |
| 비한정적(인스턴스) | String::toLowerCase | str -> str.toLowerCase() |
| 클래스 생성자 | TreeMap<K, V>::new | () -> new TreeMap<K, V>() |
| 배열 생성자 | int[]::new | len -> new int[len] |
아이템 44. 표준 함수형 인터페이스를 사용하라
핵심 정리
· 자바8 부터 람다를 지원하므로, API를 설계할 때 람다도 염두에 두어야 한다.
· 입력값과 반환값에 함수형 인터페이스 타입을 활용하자.
· 보통 java.util.function 패키지의 표준 함수형 인터페이스를 사용하는 것이 가장 좋은 선택이다.
· 단, 흔치는 않지만 직접 함수형 인터페이스를 만들어 쓰는 편이 낳을 수도 있다.
람다와 API 작성 모범 사례
· 자바가 람다를 지원하면서 API를 작성하는 모범 사례도 크게 바뀌었다.
- 상위 클래스의 기본 메서드를 재정의해 원하는 동작을 구현하는 템플리 메서드 패턴[Gamma95]의 매력이 크게 줄었다. 이를 대체하는 현대적인 해법은 같은 효과의 함수 객체를 받는 정적 팩터리나 생성자를 제공하는 것이다.
· 위 내용을 일반화하면, 함수 객체를 매개변수로 받는 생성자와 메서드를 더 많이 만들어야 한다.
- 이때 함수형 매개변수 타입을 올바르게 선택해야 한다.
함수 객체를 매개변수로 사용하는 예시
LinkedHashMap의 protected 메서드인 removeEldestEntry를 재정의하면 캐시로 사용할 수 있다. 맵에 새로운 키를 추가하는 put 메서드는 이 메서드를 호출하여 true가 반환되면 맵에서 가장 오래된 원소를 제거한다.
다음 처럼 removeEldestEntry를 재정의하면 맵에 가장 최근 원소 100개를 유지한다.
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > 100;
}
위 코드는 잘 동작하지만, 람다를 사용하면 훨씬 잘 해낼 수 있다. LinkedHashMap을 오늘날 다시 구현한다면, 함수 객체를 받는 정적 팩터리나 생성자를 제공했을 것이다.
removeEldestEntry는 size()를 호출해 맵 안의 원소 수를 알아낸다. removeEldestEntry가 인스턴스 메서드라 가능한 방식이다. 하지만 생성자에 넘기는 함수 객체는 이 맵의 인스턴스 메서드가 아니다. 팩터리나 생성자를 호출할 때는 맵의 인스턴스가 존재하지 않기 때문이다. 따라서 맵은 자기 자신도 함수 객체에 건네줘야 한다.
이를 반영한 함수형 인터페이스는 다음과 같다.
// 불필요한 함수형 인터페이스 - 대신 표준 함수형 인터페이스를 사용하라.
@FunctionalInterface interface EldestEntryRemovalFunction<K,V> {
boolean remove( Map<K,V> map, Map.Entry<K,V> eldest );
}
이 인터페이스는 잘 동작하나, 굳이 사용할 이유느 없다. 자바 표준 라이브러리에 이미 같은 모양의 인터페이스가 준비되어 있다.
표준 함수형 인터페이스
· java.util.function 패키지를 보면 다양한 용도의 표준 함수형 인터페이스가 담겨 있다.
필요한 용도에 맞는 게 있다면, 직접 구현하지 말고 표준 함수형 인터페이스를 활용하자.
· 표준 함수형 인터페이스 사용의 장점:
1. API가 다루는 개념의 수가 줄어 익히기 더 쉬워 진다.
2. 표준 함수형 인터페이스들은 유용한 디폴트 메서드를 많이 제공한다. 따라서 다른 코드와의 상호운용성도 크게 좋아진다.
ex) Predicate 인터페이스는 프레디키드(predicate)들을 조합하는 메서드를 제공한다. LinkedHashMap 예에서는 직접 만든 EledestEntryRemoveFuntion 대신 표준 인터페이스인 BiPredicate<Map<K, V>>, Map.Entry<K, V>를 사용할 수 있다.
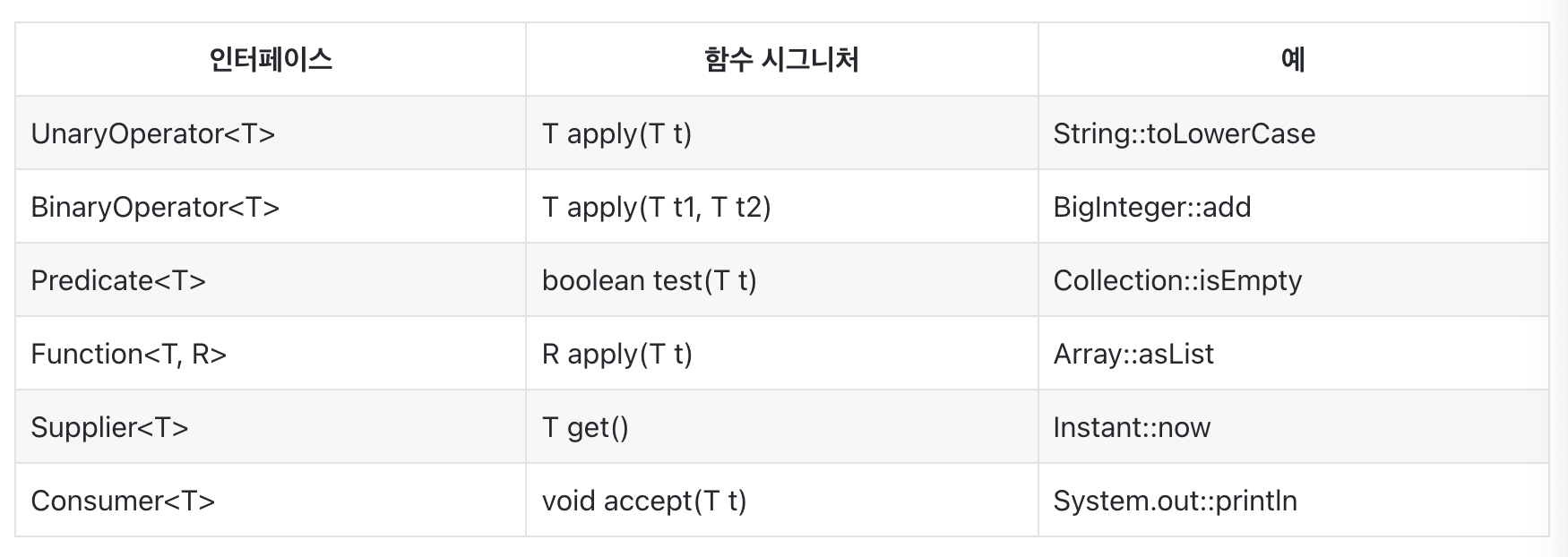
· java.util.function 패키지에는 총 43개의 인터페이스가 담겨 있다. 그 중 기본 인터페이스 6개만 기억하면 나머지를 유추할 수 있다.
- 기본 인터페이스들은 모두 참조 타입용이다.
기본 인터페이스
· Operator 인터페이스는 인수가 1개인 UnaryOperator와 2개인 BinaryOperator로 나뉘며, 반환값과 인수의 타입이 같은 함수를 뜻한다.
· Predicate 인터페이스는 인수 하나를 받아 boolean을 반환하는 함수를 뜻한다.
· Function 인터페이스는 인수와 반환 타입이 다른 함수를 뜻한다.
· Supplier 인터페이스는 인수를 받지 않고 값을 반환(혹은 제공)하는 함수를 뜻한다.
· Consumer 인터페이스는 인수를 하나 받고 반환값은 없는(특히 인수를 소비하는) 함수를 뜻한다.
다음은 기본 함수형 인터페이스들을 정리한 표다.
기본 인터페이스의 변형
· 기본 인터페이스는 기본 타입인 int, long, double용으로 각 3개씩 변형이 생긴다.
- 이름은 기본 인터페이스의 이름 앞에 해당 기본 타입 이름을 붙여 지었다.
ex) int를 받는 Predicate는 IntPredicate, long을 받아 long을 반환하는 BinaryOperator는 LongBinaryOperator가 되는 식이다.
· Function의 변형은 유일하게 반환 타입이 매개변수화된다.
ex) LongFunction<int[]>은 long 인수를 받아 int[]를 반환한다.
· Function 인터페이스에는 기본 타입을 반환하는 변형이 총 9개 더 있다.
- 입력과 결과 타입이 모두 기본 타입이면 접두어로 SrcToResult를 사용한다(총 6개).
ex) long을 받아 int를 반환하면 LongToIntFunction이 되는 식이다.
- 나머지는 입력이 객체 참조이고 결과가 int, long, double인 변형들로, 앞서와 달리 입력을 매개변수화하고 접두어로 ToResult를 사용한다(총 3개).
ex) int[] 인수를 받아 long을 반환하면 ToLongFunction<int[]>이 되는 식이다.
· 기본 함수형 인터페이스 중 3개에는 인수를 2개씩 받는 변형이 있다(총 6개).
- BiPredicate<T, U>, BiFunction<T,U,R>, BiConsumer<T,U>이다.
- BiFunction은 기본 타입을 반환하는 세 변형 ToIntBiFunction<T,U>, ToLongBiFunction<T,U>, ToDoubleBiFunction<T,U>가 존재한다.
· Consumer에는 객체 참조와 기본 타입 하나, 즉 인수를 2개 받는 변형인 ObjDoubleConsumer<T>, ObjIntConsumer<T>, ObjLongConsumer<T>가 존재한다(총 3개).
- 이렇게 해서 기본 인터페이스의 인수 2개짜리 변형을 총 9개다.
· BooleanSupplier 인터페이스는 boolean을 반환하도록 한 Supplier의 변형이다.
- 이것은 표준 함수형 인터페이스 중 boolean을 이름에 명시한 유일한 인터페이스다.
- 하지만 Predicate와 그 변형 4개도 boolean 값을 반환할 수 있다.
· 표준 함수형 인터페이스 대부분은 기본 타입만 지원한다. 하지만 여기에 박싱된 기본 타입을 넣어 사용하지는 말자
- 계산량이 많을 떄 성능이 처참히 느려질 수 있다(아이템 61).
전용 함수형 인터페이스 직접 작성해야 할 때
· 대부분 상황에서 직접 작성하는 것보다 표준 함수형 인터페이스를 사용하는 편이 낫지만, 코드를 직접 작성해야할 때도 있다.
· 표준 인터페이스 중 필요한 용도에 맞는 게 없다면 직접 작성해야 한다.
ex) 매개변수 3개를 받는 Predicate, 검사 예외를 던지는 경우
· 구조적으로 똑같지만, 다음을 하나 이상 만족한다면 직접 작성하는 것을 고려한다.
1. 자주 쓰이며, 이름 자체가 용도를 명확히 설명한다.
2. 반드시 따라야 하는 규약이 있다.
3. 유용한 디폴트 메서드를 제공할 수 있다.
예를 들어 Comparator<T> 인터페이스는 구조적으로 ToIntBiFunction<T,U과 동일하지만, 위와 같은 특성을 모두 지니기 때문에 전용 함수형 인터페이스가 만들어졌다.
전용 함수형 인터페이스 설계하기
· 전용 함수형 인터페이스를 작성하기로 했다면, 작성하는 게 '인터페이스'임을 명심하고 주의해서 설계해야 한다.
· 함수형 인터페이스에 @FunctionalInterface 애너테이션을 달면, 다음의 효과를 볼 수 있다.
1. 해당 클래스의 코드나 설명 문서를 읽을 이에게 그 인터페이스가 람다용으로 설계된 것임을 알려준다.
2. 해당 인터페이스가 추상 메서드를 오직 하나만 가지고 있어야 컴파일되게 해준다.
3. 2번의 결과로, 유지보수 과정에서 누군가 실수로 메서드를 추가하지 못하게 막아준다.
위와 같은 이점이 있으니, 직접 만든 함수형 인터페이스에는 항상 @FunctionalInterface 애너테이션을 사용하자.
주의 사항! 서로 다른 함수형 인터페이스를 같은 위치의 인수로 받는 메서드들을 다중 정의해서는 안된다.
- 클라이언트에게 불필요한 모호함만 안겨준다.
ex) ExecutorService의 submit 메서드는 Callable<T>를 받는 것과 Runnable을 받는 것을 다중정의했다. 그래서 올바른 메서드를 알려주기 위해 형변환해야 할 때가 왕왕 생긴다(아이템 52).
아이템 45. 스트림은 주의해서 사용하라
핵심 정리
· 스트림을 사용해야 멋지게 처리할 수 있는 일이 있고, 반복 방식이 더 알맞은 일도 있다.
· 많은 작업들이 이 둘을 조합했을 때 가장 멋지게 해결된다.
· 어느 쪽을 선택하는 확고부동한 규칙은 없지만 참고할 만한 지침 정도는 있다.
· 어느 쪽이 나은지 확연히 드러나는 경우가 많겠지만, 아니더라도 방법은 있다.
· 어느 쪽이 나은지 확신하기 어렵다면, 둘 다 해보고 더 나은 쪽을 택하라.
스트림 API의 핵심
· 스프링 API의 목적: 스트링 API는 대량 데이터 처리 작업(순차적이든 병렬적이든)을 돕고자 자바 8에 추가되었다.
· 스트림 API가 제공하는 추상 개념 중 핵심은 두 가지다.
1. 데이터 원소의 유한 또는 무한 시퀸스(sequence)
2. 스트림 파이프라인: 이 원소들로 수행하는 연산 단계를 표현하는 개념
- 스트림 원소들은 어디로부터든 올 수 있다. ex) 컬렉션, 배열, 파일, 정규표현식 패턴 매처, 난수 생성기, 다른 스트림
- 스트림 안의 데이터 원소들은 객체 참조나 기본 타입 값이다. 기본 타입 값으로 int, long, double 세 가지를 지원한다.
스트림 파이프라인
· 스트림 파이프라인은 소스 스트림에서 시작해 종단 연산(terminal operation)으로 끝나며, 그 사이에 하나 이상의 중간 연산(intermediate operation)이 있을 수 있다.
- 각 중간 연산은 스트림을 어떠한 방식으로 변환(transform)한다. ex) 특정 조건을 만족 못하는 원소를 걸러난다.
- 변환된 스트림의 원소 타입은 변환 전 스트림의 원소 타입과 같은 수도 있고, 다를 수도 있다.
- 종단 연산은 마지막 중간 연산이 내놓은 스트림에 최후의 연산을 가한다. ex) 원소를 정렬해 컬렉션에 담거나, 특정 원소 하나를 선택하거나, 모든 원소를 출련하는 식이다.
· 스트림 파이프라인은 지연 평가(lazy evaluation)된다.
- 평가는 종단 연산이 호출될 때 이뤄지며, 종단 연산에 쓰이지 않는 데이터 원소는 계산에 쓰이지 않는다.
- 지연 평가는 무한 스트림을 다룰 수 있게 해주는 열쇠다.
주의 사항! 종단 연산을 빼먹지 말자. 종단 연산이 없는 스트림 파이프라인은 아무 일도 하지 않는다.
· 스트림 API는 메서드 연쇄를 지원하는 플루언트 API다.
- 즉, 파이프라인 하나를 구성하는 모든 호출을 연결하여 단 하나의 표현식으로 완성할 수 있다.
- 파이프라인 여러 개를 연결해 표현식 하나로 만들 수 있다.
· 기본적으로 스트림 파이프라인은 순차적으로 수행된다.
- 파이프라인을 병렬로 실행하려면 파이프라인을 구성하는 스트림 중 하나에서 parallel 메서드를 호출하면 된다.
하지만 효과를 볼 수 있는 상황은 많지 않다(아이템 48).
· 스트림 API는 다재다능하여 사실상 어떠한 계산도 할 수 있다.
스트림의 과용
· 스트림을 제대로 사용하면 프로그램이 짧고 깔끔해지지만, 잘못 사용하면 읽기 어렵고 유지보수도 힘들어진다.
사전 파일에서 단어를 읽어 사용자가 지정한 문턱값보다 원소 수가 많은 아나그램 그룹을 출력하는 프로그램을 살펴보자.
- 아나그램: 철자를 구성하는 알파벳을 같고 순서만 다른 단어
프로그램 설명↓
이 프로그램은 사용자가 명시한 사전 파일에서 각 단어를 읽어 맵에 저장한다. 맵의 키는 그 단어를 구성하는 철자들을 알파벳순으로 정렬한 값이다. 즉, "staple"의 키는 "aelpst"가 되고, "petals"의 키도 "aelpst"가 되어 두 단어는 아나그램이고, 같은 키를 공유한다. 맵의 값은 같은 키를 공유한 단어들을 담은 집합이다. 사전 하나를 모두 처리하면, 각 집합은 사전에 등재된 아나그램들을 모두 담은 상태가 된다. 이 프로그램은 맵의 values() 메서드로 아나그램 집합들을 얻어 원소 수가 문턱값보다 많은 집합들을 출력한다.
// 사전 하나를 훑어 원소 수가 많은 아나그램 그룹들을 출력한다.
public class Anagrams {
public static void main(String[] args) throws IOException {
File dictionary = new File(args[0]);
int minGroupSize = Integer.parseInt(args[1]);
Map<String, Set<String>> groups = new HashMap<>();
try (Scanner s = new Scanner(dictionary)) {
while (s.hasNext()) {
String word = s.next();
groups.computeIfAbsent(alphabetize(word), (unused) -> new TreeSet<>()).add(word);
}
}
for (Set<String> group : groups.values())
if (group.size() >= minGroupSize)
System.out.println(group.size() + ": " + group);
}
private static String alphabetize(String s) {
char[] a = s.toCharArray();
Arrays.sort(a);
return new String(a);
}
}
프로그램의 첫 번째 단계에서 맵에 각 단어를 삽입할 때 자바 8에 추가된 computeIfAbsent 메서드를 사용했다. 해당 메서드를 사용하면 각 키와 값을 매핑해놓고, 계산된 값을 반환한다.
- computeIfAbsent: 맵 안에 키가 있는지 찾은 다음, 있으면 그 키에 매핑된 값을 반환한다. 키가 없으면 건네진 함수 객체를 키에 적용하여 값을 계산해낸 다음 그 키와 값을 매핑해놓고, 계산된 값을 반환한다.
다음 프로그램은 앞의 코드와 같은 일을 하지만 스트림을 과하게 활용한다.
- 사전 파일을 여는 부분만 제외하면 프로그램 전체가 단 하나의 표현식으로 처리된다.
- 짧지만 읽기 어렵다.
이처럼 스트림을 과용하면 프로그램이 읽거나 유지보수하기 어려워진다.
// 스트림을 과하게 사용했다 - 따라 하지 말 것!
public class Anagrams {
public static void main(String[] args) throws IOException {
Path dictionary = Paths.get(args[0]);
int minGroupSize = Integer.parseInt(args[1]);
try (Stream<String> words = Files.lines(dictionary)) {
words.collect(
groupingBy(word -> word.chars().sorted()
.collect(StringBuilder::new,
(sb, c) -> sb.append((char) c),
StringBuilder::append).toString()))
.values().stream()
.filter(group -> group.size() >= minGroupSize)
.map(group -> group.size() + ": " + group)
.forEach(System.out::println);
}
}
}
다음은 프로그램은 앞서 두 프로그램과 같지만 스트림을 적당히 사용했다. 그 결과 원래 코드보다 짧을 뿐 아니라 명확하다.
// 스트림을 적절히 활용하면 깔끔하고 명료해진다.
public class Anagrams {
public static void main(String[] args) throws IOException {
Path dictionary = Paths.get(args[0]);
int minGroupSize = Integer.parseInt(args[1]);
try (Stream<String> words = Files.lines(dictionary)) {
words.collect(groupingBy(word -> alphabetize(word)))
.values().stream()
.filter(group -> group.size() >= minGroupSize)
.forEach(g -> System.out.println(g.size() + ": " + g));
}
}
// alphabetize 메서드는 코드 이전과 같다.
}
alphabetize 메서드도 스트림을 사용해 다르게 구현할 수 있지만, 그렇게 하면 명확성이 떨어지고 잘못 구현할 가능성이 커진다. 심지어 느려질 수도 있다. 자바가 기본 타입인 char용 스트림을 지원하지 않기 때문이다.
· 람다 매개변수의 이름은 주의해서 정하자.
- 람다에서는 타입 이름을 자주 생략하므로 매개변수 이름을 잘 지어야 스트림 파이프라인의 가동성이 유지된다.
- 앞 코드에서 매개변수 g는 사실 group이 라고 하는게 낫다.
· 도우미 메서드를 적절히 활용하는 일의 중요성은 일반 반복 코드에서보다는 스트림 파이프라인에서 훨씬 크다.
- 파이프라인에서는 타립 정보가 명시 되지 않거나 임시 변수를 자주 사용하기 때문이다.
- 위 코드에서는 단어의 철자를 알파벳순으로 정렬하는 일을 별도 메서드인 alphabetize에서 수행했다. 이를 통해 연산에 적절한 이름을 지어주고, 세부 구현을 주 프로그램 로직 밖으로 빼내 전체적인 가독성을 높인다.
· 스트림 파이프라인은 되풀이되는 계산을 함수 객체로 표현했고, 반복 코드에서는 코드 블록을 사용해 표현했다.
스트림과 char
다음은 char 값들을 스트림으로 처리하는 코드다.
"Hello world!".chars().forEach(System.out::print);
위 코드는 Hello world!를 출력하리라 기대되지만, 721011081081113211911111410810033을 출력한다.
"Hello world!".chars()가 반환하는 스트림의 원소는 char가 아닌 int 값이기 때문이다.
이처럼 이름이 chars인데 int 스트림을 반환하면 헷갈릴 수 있다. 올바른 print 메서드를 호출하게 하려면 다음처럼 형변환을 명시적으로 해줘야한다.
· 하지만 char 값들을 처리할 때는 스트림을 삼가는 편이 낫다.
스트림 올바르게 사용하기
· 스트림으로 바꾸는 게 가능해도 코드 가독성과 유지보수 측면에서 손해 볼 수 있으므로 주의하자.
· 스트림과 반복문을 적절히 조합하는 게 최선이다.
· 기존 코드는 스트림을 사용하도록 리팩터링하되, 새 코드가 더 나아 보일 때만 반영하자.
코드블럭에 안성맞춤인 일
· 함수 객체로는 할 수 없지만, 코드 블록으로는 할 수 있는 일들이다.
1. 코드 블록에서는 범위 안의 지역변수를 읽고 수정할 수 있다. 하지만 람다에서는 final이거나 사실상 final인 변수만 읽을 수 있고, 지역변수를 수정하는 건 불가능하다.
2. 코드 블록에서는 return 문을 사용해 메서드에서 빠져나가거나, break나 continue 문으로 블록 바깥의 반복문을 종료하거나 반복을 한 번 건너뛸 수 있다. 또한 메서드 선언에 명시된 검사 예외를 던질 수 있다. 람다로는 이중 어떤 것도 할 수 없다.
스트림에 안성맞춤인 일
· 이 중 하나를 수행하는 로직이라면, 스트림을 적용하기 좋은 후보다.
1. 원소들의 시퀸스를 일관되게 변환한다.
2. 원소들의 시퀸스를 필터링한다.
3. 원소들의 시퀸스를 하나의 연산을 사용해 결합한다. ex) 더하기, 연결하기, 최솟값 구하기 등
4. 원소들의 시퀸스를 컬렉션에 모은다(아마도 공통된 속성을 기준으로 묶어가며).
5. 원소들의 시퀸스에서 특정 조건을 만족하는 원소를 찾는다.
스트림으로 처리하기 어려운 일
· 대표적인 예: 한 데이터가 파이프라인의 여러 단계를 통과할 때 이 데이터의 각 단계에서 값들을 동시에 접근하기 어려운 경우
- 원인: 스트림 파이프라인은 일단 한 값을 다른 값에 매핑하고 나면 원래의 값은 읽는 구조이기 때문이다.
원래 값과 새로운 값의 쌍을 저장하는 객체를 사용해 매핑하는 우회 방법도 있지만, 만족스러운 해법은 아니다. 특히 매핑 객체가 필요한 단계가 여러 곳이면 더 그렇다.
- 이런 방식은 코드 양도 많고 지저분하여 스트림을 쓰는 주목적에서 벗어난다.
가능한 경우라면, 앞 단계의 값이 필요할 때 매핑을 거꾸로 수행하는 방법이 낫다.
처음 20개의 메르센 소수를 출력하는 프로그램을 작성해보자. 메르센 수는 2^p - 1 형태의 수다. p가 소수면, 해당 메서센 수도 소수일 수 있는데, 이를 메르센 소수라 한다. 이 파이프라인의 첫 스트림으로는 모든 소수를 사용할 것이다.
다음 코드는 무한 스트림을 반환하는 메서드다. BigInteger의 정적 멤버들은 정적 임포트하여 사용한다.
static Stream<BigInteger> primes(){
return Stream.iterate(TWO, BigInteger::nextProbablePrime);
}
메서드 이름 primes는 스트림의 원소가 소수임을 말해준다.
- 스트림을 반환하는 메서드 이름은 이처럼 원소의 정체를 알려주는 복수 명사로 쓰기를 추천한다. 스트림 파이프라인의 가독성이 크게 좋아질 것이다.
Stream.iterate라는 정적 팩터리는 매개변수를 2개 받는다. 첫 번째는 스트림의 첫 번째 원소고, 두 번째는 스트림에서 다음 원소를 생성해주는 함수다.
다음은 처음 20개의 메르센 소수를 출력하는 프로그램이다. 소수들을 사용해 메르센 수를 계산하고, 결과값이 소수인 경우만 남기고, 결과 스트림의 원소 수를 20개로 제한하고, 작업이 끝나면 결과를 출력한다.
- 매직넘버 50은 소수성 검사가 true를 반환할 확률을 제어한다.
public static void main(String[] args){
primes().map(p -> TWO.pow(p.intValueExact()).subtract(ONE))
.filter(mersenne -> mersenne.isProbablePrime(50))
.limit(20)
.forEach(System.out :: println);
}
각 메르센 소수의 앞 지수(p)를 출력하길 원한자고 해보자. 첫 번째 중간 연산에서 수행한 매핑을 거꾸로 수행해 메르센 수의 지수를 쉽게 계산할 수 있다.
지수는 단순히 숫자를 이진수로 표현한 다음 몇 비트인지 세면 나오므로, 종단 연산을 다음처럼 작성하면 원하는 결과를 얻을 수 있다.
.forEach(mp -> System.out.println(mp.bitLength() + " : " + mp));
스트림과 반복 중 어느 쪽을 써야 할지 바로 알기 어려운 작업
이러한 작업의 예로 카드 덱을 초기화하는 작업을 생각해보자. 카드는 숫자(rank)와 무늬(suit)을 묶은 불변 값 클래스이고, 숫자와 무늬는 모두 열거 타입이다.
이 작업은 두 집합의 원소들로 만들 수 있는 가능한 모든 조합을 계산하는 문제다. 수학자들은 이를 두 집합 데카르트 곱이라고 부른다.
다음은 for-each 반복문을 중첩해 구현한 코드다.
private static List<Card> newDeck(){
List<Card> result = new ArrayList<>();
for(Suit suit : Suit.values())
for(Rank rank : Rank.values())
result.add(new Card(suit, rank));
return result;
}
다음은 스트림으로 구현한 코드다. 중간 연산으로 사용한 flatMap은 스트림의 원소 각각을 하나의 스트림으로 매핑한 다음, 그 스트림들을 다시 하나의 스트림으로 합친다. 이를 위해 중첩된 람다를 사용했다.
- 이를 평탄화(flattening)이라고 한다.
private static List<Card> newDeck(){
return Stream.of(Suit.values())
.flatMap(suit ->
Stream.of(Rank.values())
.map(rank -> new Card(suit, rank)))
.collect(toList());
}
· 이러한 두 코드는 개인의 취향과 프로그래밍 환경의 문제다.
- 이해하고 유지 보수하기에 처음 코드가 더 편한 프로그래머가 많을 것이다.
- 스트림 방식이 나아 보이고, 동료들도 스트림 코드를 이해할 수 있고 선호한다면 스트림 방식을 사용하자.
- 확신이 서지 않는다면, 첫 번째 방식을 쓰는 게 안전할 것이다.
아이템 46. 스트림에서는 부작용 없는 함수를 사용하라
핵심 정리
· 스프림 파이프라인 프로그래밍의 핵심은 부작용 없는 함수 객체에 있다.
· 스트림뿐 아니라 스트림 관련 객체에 건네지는 모든 함수 객체가 부작용이 없어야 한다.
· 종단 연산 중 forEach는 스트림이 수행한 계산 결과를 보고할 때만 이용해야 한다. 계산 자체에는 이용하지 말자.
· 스트림을 올바로 사용하려면 수집기를 잘 알아둬야 한다.
- 가장 중요한 수집기 팩터리는 toList, toSet, toMap, groupingBy, joining이다.
스트림 API의 특징
· 스프림은 그저 또 하나의 API가 아닌, 함수형 프로그래밍에 기초한 패러다임이다.
- 스트림이 제공하는 표현력, 속도, 병렬성을 얻으려면 API 뿐만 아니라 이 패러다임까지 함께 받아들여야 한다.
· 스트림 패러다임의 핵심은 계산을 일련의 변환으로 재구성 하는 부분이다. 이때 각 변환 단계는 가능한 이전 단계의 결과를 받아 처리하는 순수 함수여야 한다.
- 이렇게 하려면 중간 단계든 종단 단계든 스트림 연산에 건네는 함수 객체는 모두 부작용(side effect)이 없어야 한다.
- 순수 함수: 오직 입력만이 결과에 영향을 주는 함수다. 다른 가변 상태를 참조하지 않고, 함수 스스로도 다른 상태를 변경하지 않는다.
스트림 패러다임을 이해하지 못한 예시
다음은 텍스트 파일에서 단어별 수를 세어 빈도표로 만드는 프로그램이다.
// 스트림 패러다임을 이해하지 못한 채 API만 사용했다 - 따라 하지 말 것!
Map<String, Long> freq = new HashMap<>();
try(
Stream<String> words = new Scanner(file).tokens())
words.forEach(word -> {
freq.merge(word.toLowerCase(), 1L, Long::sum);
});
}
스트림, 람다, 메서드 참조를 사용했고, 결과도 올바르지만 스트림 코드라 할 수 없다. 스트림 코드를 가장한 반복코드다.
- 스트림 API의 이점을 살리지 못하여 같은 기능의 반복적 코드보다 길고, 어렵고, 유지보수에도 좋지 않다.
· 문제점: forEach에서 외부 상태(빈도표)를 수정하는 람다를 실행한다.
스트림을 제대로 활용한 예시
다음은 위 코드를 올바르게 수정한 모습이다.
Map<String, Long> freq;
try (Stream<String> words = new Scanner(file).tokens()) {
freq = words.collect(groupingBy(String::toLowerCase, counting()));
}
· 이전 코드와 같은 일을 하지만, 이번엔 스트림 API를 제대로 사용했고, 짧고 명확하다.
· forEach 연산은 스트림 계산 결과를 보고할 때만 사용하고, 계산하는 데는 쓰지 말자.
- forEach 연산은 종단 연산 중 기능이 가장 적고, 가장 '덜' 스트림답다. 대놓고 반본적이어서 병렬화할 수도 없다.
· Scanner의 스트림 메서드인 tokens를 사용해 스트림을 얻었다.
- 자바 9부터 지원하는 메서드로, 그 이전 버전을 쓰는 사람은 어댑터를 이용하여 (Iterator를 구현한) Scanner를 스트림으로 변환할 수 있다. 아이템 47에서 사용되는 streamOf(Iterable<E>)가 좋은 예다.
스트림을 올바르게 사용하기 위한 기술 - 수집기(collector)
· 위 코드에서 사용하는 수집기(collector)는 스트림을 사용하려면 꼭 배워야하는 개념이다.
- 수집기가 생성하는 객체는 일반적으로 컬렉션이며, 그래서 "collector"라는 이름을 쓴다.
· java.util.Collectors 클래스는 메서드를 39개나 가지고 있고, 타입 매개변수가 5개나 되지만, 복잡한 세부 내용을 잘 몰라도 이 API의 장점을 대부분 활용할 수 있다.
- Collector 인터페이스를 축소(reduction) 전략을 캡슐화한 블랙박스 객체라고 생각할 수도 있다.
- 축소: 스트림의 원소들을 객체 하나에 취합한다는 뜻
컬렉션과 스트림
· 수집기를 사용하면 스트림의 원소를 손쉽게 컬렉션으로 모을 수 있다.
· 해당 기능을 하는 수집기는 총 세 가지로 toList(), toSet(), toCollection(collectionFactory)가 그 주인공이다.
- 이들은 차례로 리스트, 집합, 프로그래머가 지정한 컬렉션 타입을 반환한다.
앞서 배운 지식을 활용해 빈도표에서 다음과 같은 코드를 작성할 수 있다. 가장 흔한 단어 10개를 뽑아내는 스트림 파이프라인이다.
List<String> topTen = freq.keySet().stream()
.sorted(comparing(freq::get).reversed())
.limit(10)
.collect(toList());
맵과 스트림
· Collectors의 나머지 36개 메서드 중 대부분은 스트림을 맵으로 취합하는 기능이다.
- 이는 컬렉션에 취합하는 것보다 볼잡하다.
- 스트림의 각 원소는 키 하나와 값 하나에 연관되어 있다. 다수의 스트림 원소가 같은 키에 연관될 수도 있다.
· 가장 간단한 맵 수집기: toMap(keyMap, valueMapper)
- 스트림 원소를 키에 매핑하는 함수와 값에 매핑하는 함수를 인수로 받는다.
해당 수집기는 아이템 34에서 열거 타입 상수의 문자열 표현을 열거 타입 자체에 매핑하는 fromString을 구현하는데 사용했다.
private static final Map<String, Operation> stringToEnum =
Stream.of(values()).collect(
toMap(Obejct::toString, e->e));
스트림의 각 원소가 고유한 키에 매핑되어 있을 때 적합하다. 스트림 원소 다수가 같은 키를 사용한다면 파이프라인이 IllegalStateException을 던지면 종료된다.
· 복잡한 형태의 toMap이나 groupingBy는 이런 충돌을 다루는 다양한 전략을 제공한다.
ex) toMap에 키 매퍼와 값 매퍼와 함께 병합(merge) 함수까지 제공할 수 있다. 병합 함수의 형태는 BinaryOperator<U>이며, 여기서 U는 해당 맵의 값 타입이다. 같은 키를 공유하는 값들은 이 병합 함수를 사용해 기존 값에 합쳐진다. 예컨대 병합 함수가 곱셈이면, 키가 같은 모든 값(키/값 매퍼가 정함)을 곱한 결과를 얻는다.
· 인수 3개를 받는 toMap은 어떤 키와 그 키에 연관된 원소들 중 하나를 골라 연관 짓는 맵을 만들 때 유용하다.
다음 코드는 다양한 음악가의 앨범들을 담은 스트림을 가지고, 음악가와 그 음악가의 베스트 앨범을 연관 짓는다.
// 각 키와 해당 키의 특정 원소를 연관 짓는 맵을 생성하는 수집기
Map<Artist, Album> topHits = albums.collect(
toMap(Album::artist, a->a, maxBy(comparing(Album::sales))));
비교자로 BinaryOperator에서 정적 임포트한 maxBy라는 정적 팩터리 메서드를 사용한다. maxBy는 Comparator<T>를 입력받아 BinaryOperator<T>를 돌려준다. 이 경우 비교자 생성 메서드인 comparing이 maxBy에 넘겨줄 비교자를 반환하는데, 자신의 키 추출 함수로 Album:sales를 받았다.
해당 코드는 놀랍게도 우리가 풀려한 문제를 그래로 기술한 코드가 되었다. "앨범 스트림을 맵으로 바꾸는데, 이 맵은 각 음악가와 그 음악가의 베스트 앨범을 짝지은 것이다"
· 인수가 3개인 toMap은 충돌이 나면 마지막 값을 취하는 (last-write-wins) 수집기를 만들 때도 유용하다.
많은 스트림의 결과가 비결정적이다. 하지만 매핑 함수가 키 하나에 연결해준 값들이 모두 같을 때, 혹은 값이 다르더라도 모두 허용되는 값일 때 이렇게 동작하는 수집기가 필요하다.
// 마지막에 쓴 값을 취하는 수집기
toMap(keyMapper, valueMapper, (oldVal, newVal) -> newVal)
· 인수가 4개인 toMap은 네 번째 인수로 맵 팩터리를 받는다.
- 이 인수로 EnumMap이나 TreeMap처럼 원하는 특정 맵 구현체르 직접 지정할 수 있다.
· 위 세 가지 toMap에는 변종이 있다. 그중 toConcurrentMap은 병렬 실행된 후 결과로 ConcurrentHashMap 인스턴스를 생성한다.
groupingBy
· Collectors가 제공하는 메서드로 입력으로 분류 함수(classifier)를 받고, 출력으로는 원소를 카테고리별로 모아 놓은 맵을 담은 수집기를 반환한다.
- 분류함수는 입력받은 원소가 속하는 카테고를 반환한다. 이 카테고리는 해당 원소의 맵 키로 쓰인다.
· 첫 번째 버전: groupingBy 중 형태가 가장 간단한 것은 분류 함수 하나를 인수로 받아 맵을 반환한다.
- 반환된 맵에 담긴 각각의 값은 해당 카테고리에 속하는 원소를 담은 리스트다.
이는 아이템45의 아나그램 프로그램에 사용한 수집기로, 아파벳화한 단어를 알파벳화 결과가 같은 단어들의 리스트로 매핑하는 맵을 생성했다.
words.collect(groupingBy(word -> alphabetize(word)))
· 두 번째 버전: 분류함수와 함께 다운스트림 수집기를 명시하면, groupingBy가 반환하는 수집기가 리스트 이외의 값을 갖는 맵을 생성할 수 있다.
- 스트림 수집기의 역할: 카테고리의 모든 원소를 담은 스트림으로부터 값을 생성한다.
- 이 매개변수를 사용하는 가장 간단한 방법은 toSet()을 넘기는 것이다. 그러면 groupingBy는 원소들의 리스트가 아닌 집합(Set)을 값으로 갖는 맵을 만든다.
- toCollection(collectionFactory)를 건네면, 컬렉션을 값으로 갖는 맵을 생성한다.
- counting()을 건네면, 각 카테고리(키)를 해당 카테고리에 속하는 원소의 개수(깂)와 매핑한 맵을 얻는다.
Map<String, Long> freq = words.collect(groupingBy(String::toLowerCase, counting()));
· 세 번째 버전: 앞선 매개변수에 추가로 맵 팩터리를 추가로 를 지정하면, 맵과 그안에 담긴 컬렉션의 타입을 모두 지정할 수 있다.
- 예를 들어 TreeSet인 TreeMap을 반환하는 수집기를 만들 수 있다.
- 이 메서드는 점층적 인수 목록 패턴(telescoping argument list pattern)에 어긋난다. 즉, mapFactory 매개변수가 downStream 매개변수보다 앞에 놓인다.
· 위 세 가지 groupingBy 각각에 대응하여 메서드의 동시 수행 버전인 groupingByConcurrent 메서드도 있다.
- 해당 메서드는 ConcurrentHashMap 인스턴스를 만들어준다.
· goupingBy의 사촌격인 partitionBy는 분류 함수 자리에 프레디키트(predicate)를 받고 키가 Boolean인 맵을 반환한다.
- 프레디키트에 더해 다운스트림 수집기까지 입력받는 버전도 다중정의되어 있다.
- 많이 쓰이지는 않는다.
그외 메서드
· counting 메서드가 반환하는 수집기는 다운스트림 수집기 전용이다.
- Stream의 count 메서드가 직접 사용하여 같은 기능을 수행할 수 있으니 collect(counting()) 형태로 사용할 일은 전혀 없다.
- Collections에는 이런 속성의 메서드가 16개 더 있다. 그중 9개는 이름이 summing, averaging, summarizing으로 시작하며, 각각 int, long, double 스트림용으로 하나씩 존재한다.
· 다중정의된 reducing 메서드들, filteing, mapping, flatMapping, collectingAndThen 메서드가 있는데, 대부분 프로그래머는 존재를 모르고 있어도 상관없다.
- 설계 관점에서 보면, 이 수집기들은 스트림 기능의 일부를 복제하여 다운스트림 수집기를 작은 스트림처럼 동작하게 한 것이다.
· Collectors에는 이외에도 3개의 메서드가 존재하는데, 수집과는 관련이 없다.
· minBy, maxBy는 인수로 받은 비교자를 이용해 스트림에서 값이 가장 작은 혹은 가장 큰 원소를 반환한다.
- Stream 인터페이스의 min과 max 메서드를 살짝 일반화한 것이다.
- java.util.function.BinaryOperator의 minBy와 maxBy 메서드가 반환하는 이진 연산의 수집기 버전이다.
- joining은 CharSequence 인스턴스의 스트림에만 적용할 수 있다.
- 매개변수가 없는 joining은 단순히 원소들을 연결하는 수집기를 반환한다.
- 인수가 1개인 joining은 CharSequence 타입의 구분문자를 매개변수로 받는다. 그리고 연결 부위에 이 구분문자를 삽입한다.
ex) 구분문자로 쉼표(,)를 입력하면 CSV 형태의 문자열 생성한다. 단, 스트림에 쉽표를 이미 포함한 원소가 있다면 구분문자와 구별되지 않으니 유념하자.
- 인수가 3개인 joining은 구분문자에 더해 접두문자(prefix)와 접미문자(suffix)도 받는다.
ex) 접두, 구분, 접미문자를 '[', ',', ']'로 지정하여 얻은 수집기는 [came, saw, conquered]같은 문자열을 생성한다.
아이템 47. 반환 타입으로는 스트림보다 컬렉션이 낫다
핵심 정리
· 원소 시퀸스를 반환하는 메서드를 작성할 때는, 이를 스트림으로 처리하기를 원하는 사용자와 반복으로 처리하길 원하는 사용자가 모두 있음을 떠올리고, 양쪽을 다 만족시키려 노력하자.
· 컬렉션을 반환할 수 있다면 그렇게 하자.
· 반환 전부터 이미 원소들을 컬렉션에 담아 관리하고 있거나 컬렉션을 하나 더 만들어도 될 정도로 원소 개수가 적다면 ArrayList 같은 표준 컬렉션에 담아 반환하자. 그렇지 않으면 전용 컬렉션을 구현할지 고민하자.
· 컬렉션을 반환하는 게 불가능하면 스트림과 Iterable 중 더 자연스러운 것을 반환하라.
- 만약 나중에 Stream 인터페이스가 Iterable을 지원하도록 자바가 수정된다면, 그때는 안심하고 스트림을 반환하면 될 것이다(스트림 처리와 반복 모두에서 사용할 수 있으므로).
자바8 이전의 반환 타입
· 일련의 원소를 반환하는 메서드는 수업이 많으며, 자바 7까지는 이런 메서드의 반환 타입으로 Collection, Set, List 같은 컬렉션 인터페이스 또는 Iterable이나 배열을 썼다.
- 기본은 컬렉션 인터페이스였고 for-each 문에서만 쓰이거나, 반환된 원소 시퀸스가 contains(Obejct) 같은 일부 Collection 메서드를 구현할 수 없을 때는 Iterable 인터페이스를 썼다.
- 반환 원소들이 기본 타입이거나 성능에 민감한 상황이라면 배열을 썼다.
자바8 이후의 반환 타입
· 자바8에서 스트림이 등장하면서 반환 타입의 선택이 복잡한 일이 되었다.
Steam과 Iterable
· 원소 시퀸스를 반환할 때는 당연히 스트림을 사용해야한다. 하지만, 스트림은 반복(iteration)을 지원하지 않는 문제가 있다.
- Stream 인터페이스는 Iterable 인터페이스가 정의한 추상 메서드를 전부 포함하며, Iterable 인터페이스가 정의한 방식대로 동작한다. 하지만 Stream이 Iterable을 확장(extend)하지 않아서 for-each로 스트림을 반복할 수 없다.
- 이 문제를 해결해줄 멋진 우회로는 없다.
Stream의 iterator 메서드에 메서드 참조를 건네면 문제가 해결될 것 같지만, 다음 코드는 컴파일 오류를 낸다.
// 자바 타입 추론의 한계로 컴파일되지 않는다.
for (ProcessHandle ph : ProcessHandle.allProcesses()::iterator) {
// 프로세스를 시작한다.
}
이 오류를 고치려면, 메서드 참조를 매개변수화된 Iterable로 적절히 형변환해야 한다. 작동은 하지만 실전에 쓰기에 난잡하고, 직관성이 떨어진다.
// 스트림을 반복하기 위한 '끔찍한' 우회 방법
for(ProcessHandle ph : (Iterable<ProcessHandle>) ProcessHandle.allProcesses().iterator()) {
// 프로세스를 처리한다.
}
어댑터 메서드를 사용하면 상황이 나아진다. 자바는 이런 메서드를 제공하지 않지만 다음과 같이 쉽게 만들 수 있다.
- 자바의 타입 추론이 문맥을 잘 파악하여 어댑터 메서드 안에서 따로 형변환하지 않아도 된다.
// Stream<E>을 Iterable<E>로 중개해주는 어댑터
public static<E> Iterable<E> iterableOf(Stream<E> stream) {
return steam::iterator;
}
어댑터를 사용하면 어떤 스트림도 for-each 문으로 반복할 수 있다.
· Iterable에서 Steam의 기능이 필요한 경우도 있다.
- 아이템 45의 아나그램 프로그램에서 스트림 버전은 사전을 읽을 때 Files.lines 메서드를 이용했고, 반복 버전은 스캐너를 이용했다.
- 둘 중 파일을 읽는 동안 발생하는 모든 예외를 알아서 처리해준다는 점에서 Files.lines 쪽이 더 우수하다.
- 이상적으로는 반복 버전에서도 Files.lines를 써야 했다.
API가 Iterable만 반환하면, 이를 스트림 파이프라인에서 처리하기 위한 어댑터를 구현하여 문제를 해결할 수 있다.
- 자바는 이를 위한 어댑터도 제공하지 않는다.
// Iterable<E>를 Stream<E>로 중개해주는 어댑터
public static<E> Stream<E> streamOf(Iterable<E> iterable) {
return StreamSupport.stream(iterable.spliterator(), false);
}
· 객체 시퀸스를 반환하는 메서드를 작성하는데, 이 메서드가 오직 스트림 파이프라인에서만 쓰일 걸 안다면 스트림을 반환하자.
· 반환된 객체들이 반복문에서만 쓰일 걸 안다면 Iterable을 반환하자.
· 공개 API를 작성할 때는 스트림 파이프라인을 사용하는 사람과 반복문에서 쓰려는 사람 모두를 배려해야 한다.
- 사용자 대부분이 한 방식만 사용할 거라는 근거가 없다면 말이다.
Collection 인터페이스
· 원소 시퀸스를 반환하는 공개 API의 반환 타입에는 Collection이나 그 하위 타입을 쓰는 게 일반적으로 최선이다.
- Collection 인터페이스는 Iterable의 하위 타입이고, stream 메서드도 제공하니 반복과 스트림을 동시에 지원하기 떄문이다.
· Arrays 역시 Arrays.asList와 Stream.of 메서드로 손쉽게 반복과 스트림을 지원할 수 있다.
· 반환하는 시퀸스의 크기가 메모리에 올려도 안전할 만큼 작다면 ArrayList나 HashSet 같은 표준 컬렉션 구현체를 반환하는 게 최선일 수 있다. 하지만 단지 컬렉션을 반환한다는 이유로 덩치 큰 시퀸스를 메모리에 올려서는 안 된다.
전용 컬렉션
· 반환할 시퀸스가 크지만 표현을 간결하게 할 수 있다면 전용 컬렉션을 구현하는 방안을 검토하자.
주어진 집합의 멱집합을 반환하는 상황을 생각하자.
- 멱집합: 한 집합의 모든 부분집합을 원소로 하는 집합
{a, b, c}의 멱집합은 {{}, {a}, {b}, {c}, {a, b}, {a, c}, {b, c}, {a, b, c}}다. 원소 개수가 n개면 멱집합의 원소 개수는 2^n이 된다. 따라서 멱집합을 표준 컬렉션 구현체에 저장하려는 생각은 위험하다. 하지만, AbstractList를 이용하면 훌륭한 전용 컬렉션을 손쉽게 구현할 수 있다.
비결은 멱집합을 구성하는 각 원소의 인덱스를 비트 벡터로 사용하는 것이다. 인덱스의 n번째 비트 값은 멱집합의 해당 원소가 원래 집합의 n번째 원소를 포함하는지 여부를 알려준다. 따라서 0부터 2^n - 1까지의 이진수와 원소 n개인 집합의 멱집합과 자연스럽게 매핑된다.
// 입력 집합의 멱집합을 전용 컨렉션에 담아 반환한다.
public class PowerSet {
public static final <E> Collection<Set<E>> of(Set<E> s) {
List<E> src = new ArrayList<>(s);
if(src.size() > 30) {
throw new IllegalArgumentException("집합에 원소가 너무 많습니다(최대 30개).: " + s);
}
return new AbstractList<Set<E>>() {
@Override
public int size() {
return 1 << src.size();
}
@Override
public boolean contains(Object o) {
return o instanceof Set && src.containsAll((Set) o);
}
@Override
public Set<E> get(int index) {
Set<E> result = new HashSet<>();
for (int i = 0; index != 0; i++, index >>=1) {
if((index & 1) == 1) {
result.add(src.get(i));
}
}
return result;
}
};
}
}
· AbstractCollection을 활용해서 Collection 구현체를 작성할 때는 Iterable용 메서드 외에 contains와 size만 더 구현하면 된다. 이 메서드들은 손쉽게 효율적으로 구현할 수 있다.
· (반복이 시작되기 전에는 시퀸스의 내용을 확정할 수 없는 등의 사유로) contains와 size를 구현하는 게 불가능할 때는 컬럭센보다 스트림이나 Iterable을 (또는 둘 다를) 반환하는 편이 낫다.
· Collection을 반환 타입으로 쓸 때의 단점:
- 위 코드에서 입력 집합의 원소 수가 30을 넘으면 PowerSet.of가 예외를 던진다. 이는 Stream이나 Iterable이 아닌 Collection을 반환 타입으로 쓸 때의 단점을 잘 보여준다.
- Collection의 size 메서드가 int 값을 반환하므로 PowerSet.of가 반환되는 시퀸스의 최대 길이는 Integer.MAX_VALUE 혹은 2^32 -1로 제한된다.
- Collection 명세에 따르면 컬렉션이 더 크거나 심지어 무한일 때 size가 2^31 -1을 반환해도 되지만 만족스러운 해법은 아니다.
· 때로는 단순히 구현하기 쉬운 쪽을 선택하기도 한다.
입력 리스트의 연속적인 부분리스트를 모두 반환하는 메서드를 작성한다고 하자. 필요한 부분리스트를 만들어 표준 컬렉션에 담는 코드는 3줄이면 되지만, 이 컬렉션은 입력 리스트 크기의 거듭제곱만큼 메모리를 차지한다. 멱집합 때처럼 전용 컬렉션을 구현하기란 지루한 일이다. 특히 자바는 이럴 때 쓸만한 골격 Iterator를 제공하지 않는다.
하지만 입력 리스트의 모든 부분리스트를 스트림으로 구현하기는 어렵지 않다. 첫 번째 원소를 포함하는 부분리스트를 그 리스트의 프리픽스라 해보자 (예: {a,b,c}의 프리필스는 {a}, {a, b}, {a,b,c}). 같은 식으로 마지막 원소를 포함하는 부분리스트를 그 리스트의 서픽스라고 하자(예: {a,b,c}의 서픽스는 {a,b,c}, {b,c}, {c}). 이제 어떤 리스트의 부분리스트는 단순히 그 리스트의 프리픽스의 서필스에 빈 리스트 하나만 추가하면 된다.
public class SubList {
public static <E> Stream<List<E>> of(List<E> list) {
return Stream.concat(Stream.of(Collections.emptyList()),
prefixes(list).flatMap(SubList::suffixes));
}
public static <E> Stream<List<E>> prefixes(List<E> list) {
return IntStream.rangeClosed(1, list.size())
.mapToObj(end -> list.subList(0, end));
}
public static <E> Stream<List<E>> suffixes(List<E> list) {
return IntStream.rangeClosed(0, list.size())
.mapToObj(start -> list.subList(start, list.size()));
}
}
Stream.concat 메서드는 반환되는 스트림에 빈 리스트를 추가하며, flatMap 메더드(아이템 45)는 모든 프리픽스의 모든 서픽스로 구성된 하나의 스트림을 만든다. 마지막으로 프리픽스들과 서픽스들의 스트림은 IntStream.range와 IntStream.rangeClose가 반환하는 연속된 정수값들을 매핑해 만든다.
// 입력 리스트의 모든 부분리스트를 스트림으로 반환한다.
public static <E> Stream<List<E>> of(List<E> list) {
return IntStream.range(0, list.size())
.mapToObj(start ->
IntStream.rangeClosed(start + 1, list.size())
.mapToObj(end -> list.subList(start, end)))
.flatMap(x -> x);
}
아이템 48. 스트림 병렬화는 주의해서 적용하라
핵심 정리
· 계산도 올바로 수행하고 성능도 빨라질 거라는 확신 없이는 스트림 파이프라인 병렬화는 시도조차 하지 말라
· 스트림을 잘못 병렬화하면 프로그램을 오동작하게 하거나 성능을 급격히 떨어뜨린다.
· 병렬화하는 편이 낫다고 믿더라도, 수정 후의 코드가 여전히 정확한지 확인하고 운영 환경과 유사한 조건에서 수행해보며 성능지표를 유심히 관찰 하자. 계산도 정확하고 성능도 좋아졌음이 확실해졌을 때만 병렬화 버전 코드를 운영 코드에 반영하자.
자바의 동시성 프로그래밍
주류 언어 중, 동시성 프로그래밍 측면에서 자바는 항상 앞서갔다.
· 처음 릴리스된 1996년부터 스레드, 동기화, wait/notify를 지원했다.
· 자바 5부터 동시성 컬렉션은 java.util.concurrent 라이브러리와 실행자(Executor) 프레임워크를 지원했다.
· 자바 7부터 고성능 병렬 분해(parallel decom-position) 프레임워크인 포크-조인(fork-join) 패키지를 추가했다.
· 자바 8부터는 parallel 메서드만 한 번 호출하면 파이프라인을 병렬 실행할 수 있는 스트림을 지원했다.
· 자바로 동시성 프로그래밍을 작성하기가 점점 쉬워지고 있지만, 이를 올바르고 빠르게 작성하는 일은 여전히 어려운 작업이다.
스트림 파이프라인 병렬화의 잘못된 사용
· 동시성 프로그래밍을 할 때는 안전성과 응답 가능 상태를 유지하기 위해 애써야 하는데, 병렬 스트림 파이프라인 프로그래밍에서도 다를 바 없다.
아이템 45의 메르센 소수를 생성하는 프로그램을 다시 살펴보자
public class Main {
// 스트림을 사용해 처음 20개의 메르센 소수를 생성하는 프로그램
public static void main(String[] args) {
long beforeTime = System.currentTimeMillis(); //코드 실행 전에 시간 받아오기
primes().map(prime -> TWO.pow(prime.intValue()).subtract(ONE))
.filter(mersenne -> mersenne.isProbablePrime(50))
.limit(20)
.forEach(System.out::println);
long afterTime = System.currentTimeMillis(); // 코드 실행 후에 시간 받아오기
long secDiffTime = (afterTime - beforeTime)/1000; //두 시간에 차 계산
System.out.println("시간차이(m) : "+secDiffTime);
}
static Stream<BigInteger> primes() {
return Stream.iterate(TWO, BigInteger::nextProbablePrime);
}
}
다음 코드를 실행하니 7초가 걸렸다.

속도를 높이기 위해 스트림 파이프라인의 parallel()을 호출하겠다는 순진한 생각을 했다고 가정하자.
primes().map(prime -> TWO.pow(prime.intValue()).subtract(ONE))
.parallel()
.filter(mersenne -> mersenne.isProbablePrime(50))
.limit(20)
.forEach(System.out::println);
예상과는 다르게 위 코드는 아무것도 출력하지 못하면서 CPU는 90%나 잡아먹는 상태가 무한히 계속된다(응답 불가: liveness failure).
- 원인: 스트림 라이브러리가 이 파이프라인을 병렬화하는 방법을 찾아내지 못했지 때문이다.
· 환경이 아무리 좋더라도 데이터 소스가 Steam.iterate거나 중간 연산으로 limit을 쓰면 파이프라인 병렬화로 성능 개선을 기대할 수 있다.
위 코드는 두 문제를 모두 지니고 있다. 또한 파이프라인 병렬화는 limit을 다룰 때 CPU 코어가 남는다면 원소를 몇 개 더 처리한 후 제한된 개수 이후의 결과를 버려도 아무런 해가 없다고 가정한다.
그런데 이 코드의 경우 새롭게 메르센 소수를 찾을 때마다 그 전 소수를 찾을 때보다 두 배 정도 더 오래 걸린다. 즉, 원소 하나를 계산하는 비용이 대량 그 이전까지의 원소 전부를 계산한 비용을 합친 것만큼 든다는 뜻이다. 그래서 위 코드의 파이프라인읕 자동 병렬화 알고리즘이 제 기능을 못하게 마비시킨다.
· 교훈: 스트림 파이프라인을 마구잡이로 병렬화하면 안 된다. 성능이 오히려 끔찍하게 나빠질 수 있다.
스트림 파이프라인 병렬화의 올바른 사용
· 대체로 스트림 소스가 ArrayList, HashMap, HashSet, ConcurrentHashMap의 인스턴스거나 배열, int 범위, long 범위일 때 병렬화의 효과가 가장 좋다.
- 이 자료구조들은 모두 데이터를 원하는 크기로 정확하고 손쉽게 나눌 수 있어서 일을 다수의 스레드에 분배하기에 좋다.
- 나누는 작업은 Spliterator가 담당하고, Spliterator 객체는 Stream이나 Iterable의 spliterator 메서드로 얻어올 수 있다.
· 이 자료구조들은 모두 원소를 순차적으로 실행할 때의 참조 지역성(locality of reference)이 뛰어나다.
- 이웃한 원소의 참조들이 메모리에 연속하여 저장되어 있다는 뜻이다.
- 참조들이 가리키는 실제 객체가 메모리에서 서로 떨어져 있을 수 있는데, 그러면 참조 지역성이 나빠진다.
- 참조 지역성이 낮으면 스레드는 데이터가 주 메모리에서 캐시 메모리로 전송되어 오기를 기다리며 시간을 멍하니 보낸다.
- 따라서 참조 지역성을 다량의 데이터를 처리하는 벌크 연산을 병렬화할 때 아주 중요한 요소다.
- 참조 지역성이 가장 뛰어난 자료구조는 기본 타입의 배열이다. 기본 타입 배열에는 데이터 자체가 메모리에 연속해서 저장된다.
· 스트림 파이프라인의 종단 연산의 동작 방식도 병렬 수행 효율에 영향을 준다.
- 종단 연산에서 수행하는 작업량이 파이프라인 전체 작업에서 상당 비중을 차지하면서 순차적인 연산이면, 파이프라인 병렬 수행의 효과는 제한된다.
- 병렬화에 접합한 종단 연산: 가장 적합한 것은 축소(reduction)이다. 축소는 reduce 메서드 중 하나 또는, min, max, count, sum 같이 완성된 형태로 제공되는 메서드 중 하나를 선택해 수행한다. any, allMatch, noneMatch 처럼 조건에 맞으면 바로 반환되는 메서드도 병렬화에 적합하다.
- 병렬화에 부접합한 종단 연산: 가변 축소를 수행하는 Stream의 collect 메서드는 병렬화에 적합하지 않다. 컬렉션들을 합치는 부담이 크기 때문이다.
· 직접 구현한 Stream, Iterable, Collection이 병렬화의 이점을 제대로 누리게 하려면, Spliterator 메서드를 반드시 재정의하고 결과 스트림의 병렬화 성능을 강도 높게 테스트하라.
- 고효율 spliterator를 작성하기란 상당한 난이도의 일이고, 이 책에서는 다루지 않는다.
· 스트림을 잘못 병렬화하면 (응답 불가 등) 성능이 나빠질 뿐만 아니라, 결과 자체가 잘못되거나 예상 못한 동작이 발생할 수 있다.
- 결과가 잘못되거나 오작동하는 것은 안전 실패(safety failure)라 한다.
- 안전 실패는 병렬화한 파이프라인이 사용하는 mappers, filters, 프로그래머가 제공한 다른 함수 객체가 맹세대로 동작하지 않을 때 벌어질 수 있다.
- Stream 명세는 이때 사용되는 함수 객체에 관한 엄중한 규약을 정의해놨다.
ex) Stream의 reduce 연산에 건네지는 accumulator(누적기)와 combiner(결합기) 함수는 반드시 결합법칙을 만족하고, 간섭받지 않고, 상태를 갖지 않아야 한다.
- 위 요구사항을 지키지 못해도 파이프라인을 순차적으로 수행한다면 올바른 결과를 얻을 수 있다. 하지만 병렬로 수행하면 실패로 이어지기 쉽다.
- 앞서 병렬화한 메르센 소수 프로그램은 완료되더라도 출력된 소수의 순서가 올바르지 않을 수 있다. 출력 순서를 순차 버전처럼 정렬하고 싶다면 종단 연산 forEach를 forEachOrdered로 바꿔자. 이 연산은 병렬 스트림들을 순회하며 소수를 발견한 순서대로 출력되도록 보장해줄 것이다.
· 데이터 소스 스트림이 효율적으로 나눠지고, 병렬화하거나 빨리 끝나는 종단 연산을 사용하고, 함수 객체들도 간섭하지 않더라도, 파이프라인이 수행하는 진짜 작업이 병렬화에 드는 추가 비용을 상쇄하지 못하면, 성능 향상은 미미할 수 있다.
- 성능이 향상될지 추정해보는 방법: 스트림 안의 원소 수와 원소당 수행되는 코드 줄 수를 곱한다. 이 값이 최소 수십만은 되어야 성능 향상을 맛볼 수 있다.
· 스트림 병렬화는 오직 성능 최적화 수단이므로, 변경 전후로 반드시 성능을 테스트하여 사용할 가치가 있는지 확인해야 한다(아이템 67).
- 이상적으로는 운영 시스템과 흡사한 환경에서 테스트하는 것이 좋다.
- 보통은 병렬 스트림 파이프라인도 공통의 포크-조인 풀에서 수행되므로(즉, 같은 스레드 풀을 사용), 잘못된 파이프라인 하나가 시스템의 다른 부분의 성능까지 악영향을 줄 수 있다.
스트림 파이프라인 병렬화의 효과가 제대로 발휘되는 예
· 조건이 잘 갖춰지면 parallel 메서드 호춣 하나로 거의 프로세서 코어 수에 비례하는 성능 향상을 만끽할 수 있다.
다음은 스트림 파이프라인 병렬화가 효과를 제대로 발휘하는 예다. n보다 작거나 같은 소수의 개수를 계산한다.
// 소수 계산 스트림 파이프라인 - 병렬화에 적합
static long pi(long n) {
return LongStream.rangeClosed(2, n)
.mapToObj(BigInteger::valueOf)
.filter(i -> i.isProbablePrime(50))
.count();
}
다음은 위 프로그램을 병렬화 버전으로 변경한 것이다. parallel() 호출 하나를 추가한 것만으로 작업 시간이 상당히 감소한다.
// 소수 계산 스트림 파이프라인 - 병렬화 버전
static long pi(long n) {
return LongStream.rangeClosed(2, n)
.parallel() // 기존 로직에 추가된 부분
.mapToObj(BigInteger::valueOf)
.filter(i -> i.isProbablePrime(50))
.count();
}
무작위 수의 병렬화: SplittableRandom vs ThreadRandom vs Random
· 무작위 수들로 이뤄진 스트림을 병렬화하려면 ThreadLocalRandom(또는 Random)보다는 SplittableRandom 인스턴스를 이용하자.
- 해당 클래스는 정확히 이럴 때 쓰고자 설계된 것이라 병렬화하면 성능이 선형으로 증가한다.
· ThreadRandom은 단일 스레드에서 쓰고자 만들어졌다.
- 병렬 스트림용 데이터 소스로도 사용할 수 있지만, SplittableRandom만큼 빠르지는 않다.
· Random은 모든 연산을 동기화하므로, 병렬 처리하면 최악의 성능을 보인다.
출처
이펙티브자바 3판
'자바 > 이펙티브자바' 카테고리의 다른 글
| [Effective Java] 이펙티브자바 정리: 5장 제네릭 (0) | 2022.02.06 |
|---|---|
| [Effective Java] 이펙티브자바 정리: 4장 클래스와 인터페이스 (0) | 2022.01.27 |
| [Effective Java] 이펙티브자바 정리: 3장 모든 객체의 공통 메서드 (0) | 2022.01.25 |
| [Effective Java] 이펙티브자바 정리: 2장 객체 생성과 파괴 (0) | 2022.01.24 |



댓글